基于自动系统控制的狭窄空间泊车问题
- 作者:王金元,厉宇桐,黄冠硕
- 教师:李颢
- 时间:2022-01-16
1. 简介
自动泊车旨在提高驾驶舒适性和安全性,正在成为一个热门的研究话题。它帮助司机在需要大量注意力和经验的受限环境中自动驾驶他们的汽车。停车策略是通过协调控制转向角度并考虑到环境中的实际条件来完成的,以确保在可用空间内无碰撞。
随着生产力的巨大飞跃,车辆已经逐渐可以进入每个普通人的生活。然而,随着车辆数量的增长,由于城市空间资源有限,基础设施建设相对滞后,停车位的短缺逐渐成为一个严重问题。此外,不规范的停车位大大增加了停车的难度,使得停车位的短缺越来越严重,这在市中心和老城区尤为明显。在狭窄的环境中停车,不仅对自动停车系统是一个巨大的挑战,而且对有经验的人类司机也不是一件容易的事。
自动系统控制(ASC)理论提供了多种控制方法,包括经典控制、现代控制、高级控制和模型预测控制。经典控制也被称为比例-积分-导数(PID)控制,其中比例控制是为了加速系统响应,积分控制是为了消除存在的稳态误差,导数控制是为了稳定严重振荡的系统响应。现代控制方法的核心思想是状态空间建模,系统中的变量被建模为状态向量,系统被建模为响应被建模为矩阵运算,系统的演变通过控制向量进行操纵。先进的控制包括多种方法,其中滑模控制根据预先计划的路径一步步控制系统走向目标;李亚普诺夫控制用人类根据先验知识选择的特定函数控制非线性系统的演化;最优控制考虑了系统演化中的损失,并寻找开销最小的控制法;模型预测控制(MPC)寻找当前状态下的最优控制法,并总是在每个时刻做出最佳选择。
在这项工作中,我们提出了一个基于ASC方法的窄空间停车(NSP)解决方案,并在一个特定场景中获得了成功。除此之外,受ASC方法论中最优控制的启发,我们进一步对环境变量进行建模,并尝试应用强化学习方法来解决NSP问题。
2. 相关工作
以前的研究主要是利用人类的停车经验来定义停车的运动模式[4],[6],并通过结合不同的运动模式来实现自动停车。主流方法是使用模型预测控制[5]和模糊控制[6]。
Thomas等人利用模糊模型预测控制(FMPC)方法开发了一个基于手动操作经验(MOE)的自动停车系统。该系统对车辆进行精确定位,并使用四种基本驾驶模式,根据车辆的实时状态调整车辆位置。计算出当前状态与先前状态之间的误差,并利用模糊控制系统调整转向角和速度,最终实现精确停车。
Jang等人[5]提出了一种可重复编程的自动泊车方法,该方法使用环视显示器(AVM)进行精确对准和避免碰撞。路径规划的优化方法包含横向和纵向运动的两种控制方法。车辆的横向运动使用模型预测控制(MPC)进行控制,纵向控制只考虑速度因素。与基于超声波传感器的停车位检测系统相比,该系统不需要扫描过程,并且可以在没有测距传感器的情况下检测静态障碍物。该模型的缺点是,AVM是一个基于光的无源传感器,因此对光的要求很高。
He等人[4]提出了一种基于快速A*算法的自动停车方法。快速A*算法通过最初规划离散的路径点来确定在高度封闭的环境中是否能在特定时间内完成自动停车任务。离散路径点被转化为平滑路径,并通过公式选择合适的锚点。泊车过程被分为两个阶段,以它们为分割线,并为这两个阶段设计了具体的轨迹生成方法。与目前使用的路径规划技术相比,它在成功率和规划时间方面有明显的改善。
最近的一项研究[6]提出了一种使用模糊推理系统(FIS)的自动停车方法。在这种方法中,汽车的位置是由4个范围传感器提供的数据决定的。基于人类的停车经验,该系统设置了一个使用5种运动的自动停车的FIS。因此,这种自动停车方法使用人类停车经验作为训练数据,通过调整FIS的转向角和速度参数来优化模型。这种方法的缺点是,它只适用于具有理想环境尺寸的条件。此外,本研究中使用的测距传感器会导致模糊系统在模拟中产生错误的局部优化,当汽车的每个角落的距离数据相似时。一个更好的选择是对汽车的每一面进行垂直于距离数据的建模。在这种情况下,汽车每一侧的距离测量值是相互独立的。
本文提出了一种基于人类经验和模型预测控制的自动停车方法。给定一个停车任务,根据汽车的角度将停车过程分为两个阶段,并应用不同的轨迹生成相应的策略,最终完成无碰撞的停车过程。本文还提出了一个使用强化学习进行自动停车的想法。
3. 混合控制法
3.1 控制策略
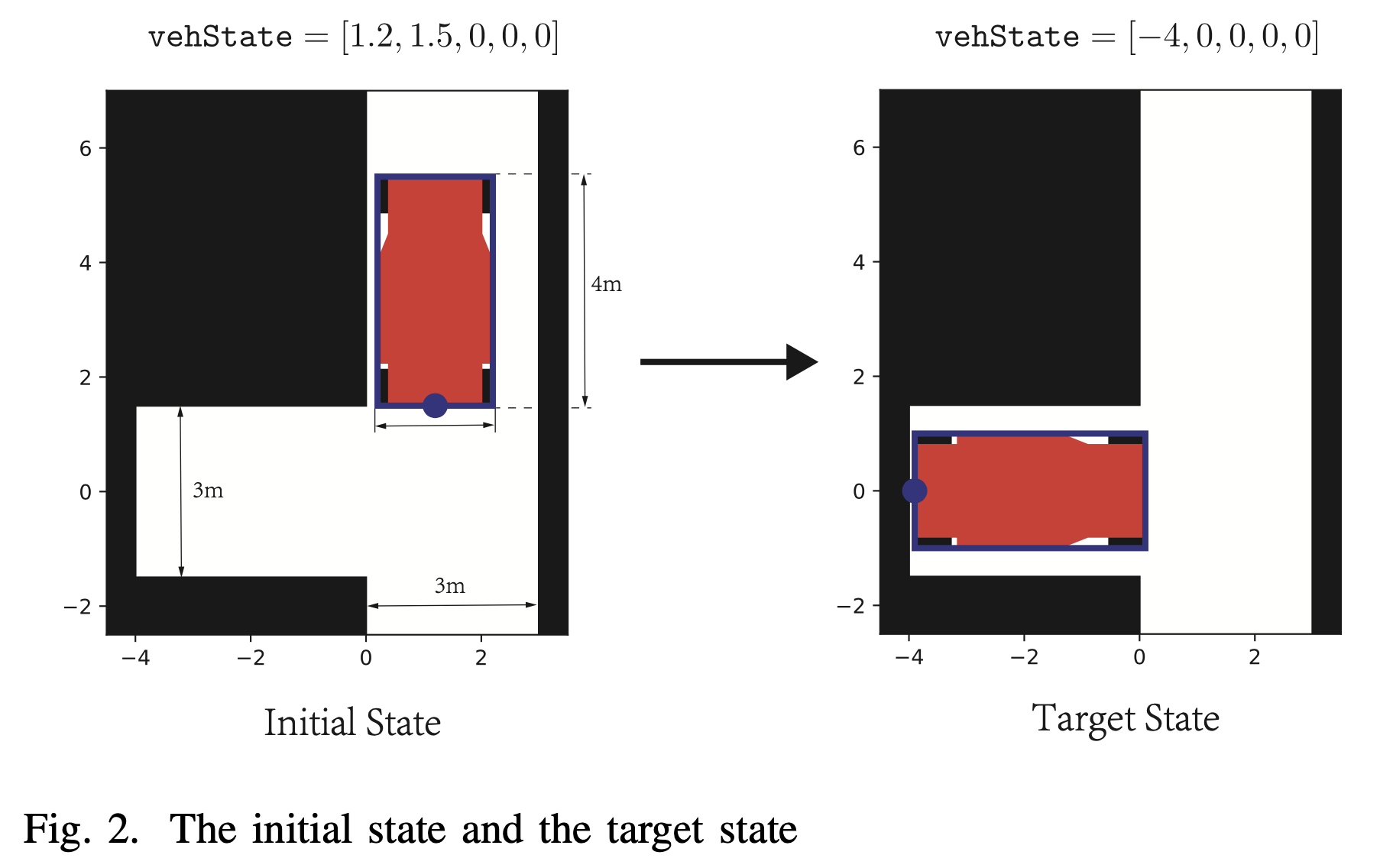
在这项工作中,车辆的位置和运动被建模为矢量vehState,其中包含5个变量,包括水平位置、垂直位置、偏航角、转向角和速度。坐标表示车辆左后和右后端点的中点位置。为了简化我们的研究,我们对转向角设置了一个约束条件: 值得注意的是,在实际执行中,我们设置,以避免的爆炸。在实践中,我们操纵steerAngIn来实现横向控制,speedIn来实现纵向控制。
我们提出的混合控制策略是一个两阶段的过程,包括一个受人类智能启发的四阶段经验规则微调阶段和一个采用状态空间建模控制方法的瞬时微调阶段。
3.2 经验性规则微调
受人类行为的启发,我们设计了一个基于经验规则的四阶段微调阶段,如图3所示。
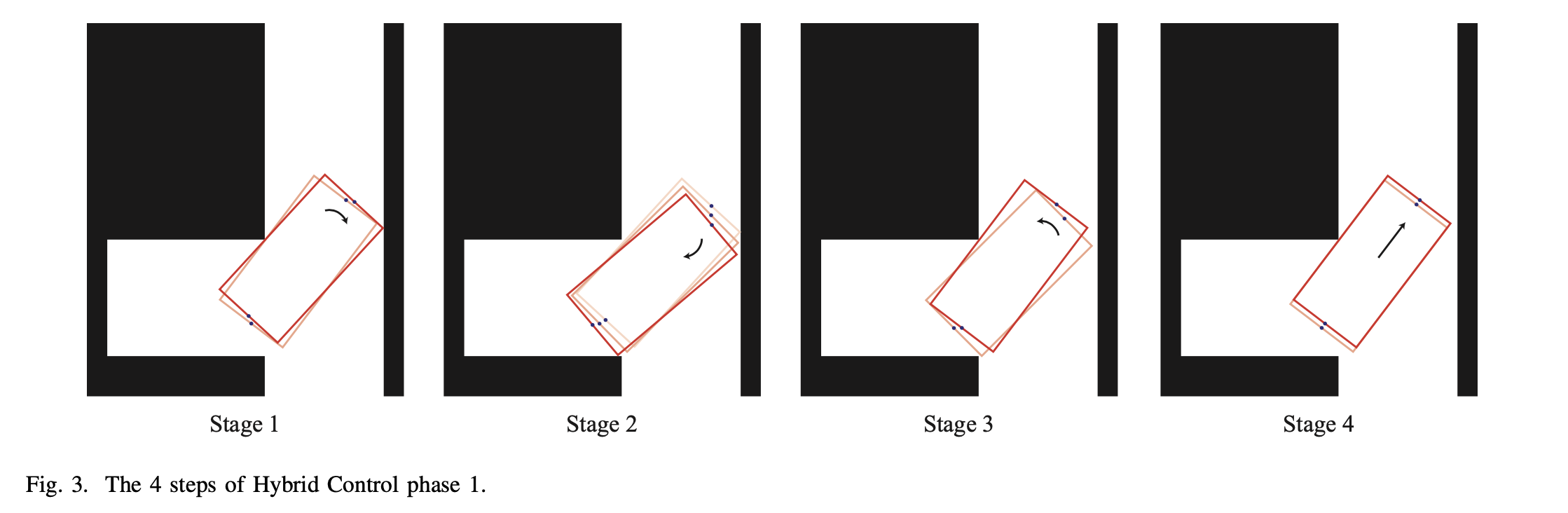
3.2.1 阶段1
第一阶段的运动是向右水平前进,这将大大减少车辆的偏航角。在时刻的转向角可以通过以下方式控制。 由于我们的模型依次实现了横向控制和纵向控制,同步控制法会导致位置推导。具体来说,在时刻,车辆开始向左水平移动,现在我们控制。在一个时间跨度之后,我们有,而在这个时间跨度,这导致位置的衍生。为了中和这个位置误差,我们在这个阶段开始时通过模型预测的偏航角来确定的转向角,而不是。
当MPC检测到近期的碰撞时,阶段1结束。
3.2.2 阶段2
第二阶段的运动是垂直向后移动,这将大大减少车辆的偏航角。在时刻的转向角可以通过以下方式控制。
当MPC检测到近期的碰撞时,第二阶段结束。
3.2.3 阶段3
第三阶段的运动是逆时针旋转,这是为下一个循环做准备。在时刻的转向角可以通过以下方式控制。
在最后阶段结束时,车辆的尾部与障碍物的左下方相连。根据人工经验,我们发现车辆的位置总是倾向于远离左上方的障碍物。因此有必要在舞台上增加一个台阶,使车辆靠近左上方。这使我们有足够的空间来调整车辆的位置和角度。所以为了达到这个目的,我们把转向角增加到最大。由于我们将最大的车轮偏转角度设置为接近,车辆在左转阶段几乎没有来回移动,这也大大增加了车辆的移动空间。
3.2.4 阶段4
第四阶段的运动是向前移动一个合适的距离。时刻的转向角可以通过以下方式控制。
在最后阶段开始之前,我们的车辆被固定在障碍物左上方的凸起上,车辆的后部被固定在障碍物的左下方。在这一点上,我们的目标是使车辆远离左下角的障碍物。因此,在这个阶段,我们将的角度设置为0,使车辆直行。在这个阶段,我们使用MPC检测车辆在近期内继续移动是否会与右墙发生碰撞。如果在不久的将来发生了碰撞,这个阶段就结束了,下一个循环开始。
3.3 瞬时微调
我们在ASC中采用了状态空间建模的方法来实现第二阶段的瞬时微调。假设 是我们模型的状态向量,系统的演化可以描述为公式1,其中 是控制向量。
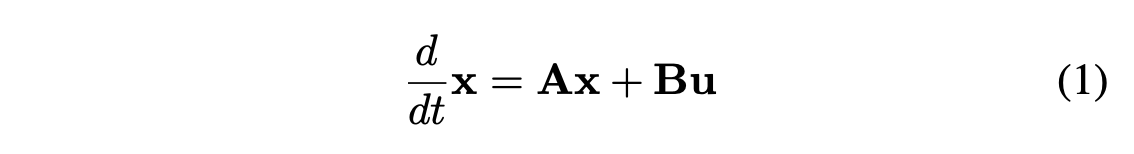
我们的目标是产生 使得 . 为了寻找这样一个 ,我们需要找到一个 使得 .
对于 ,我们有 其中 的所有特征值(eigenvalue)都有负实部.
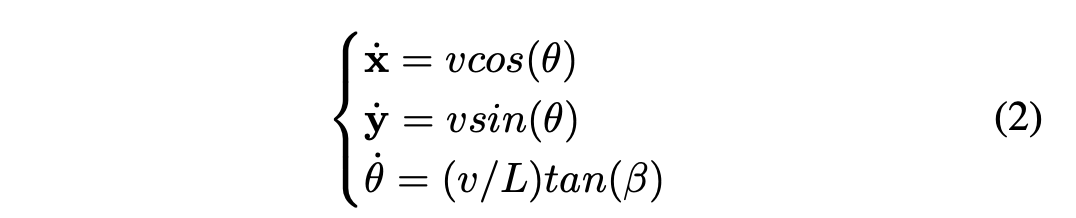
在智能车辆控制的情况下,我们根据公式2对系统的演变进行建模。
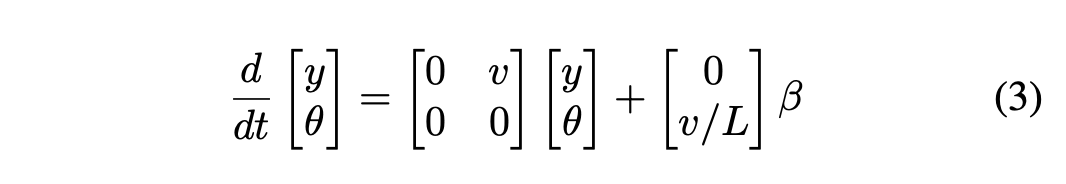
在这一阶段,系统的演变与横向近似可以进一步用公式3表示。
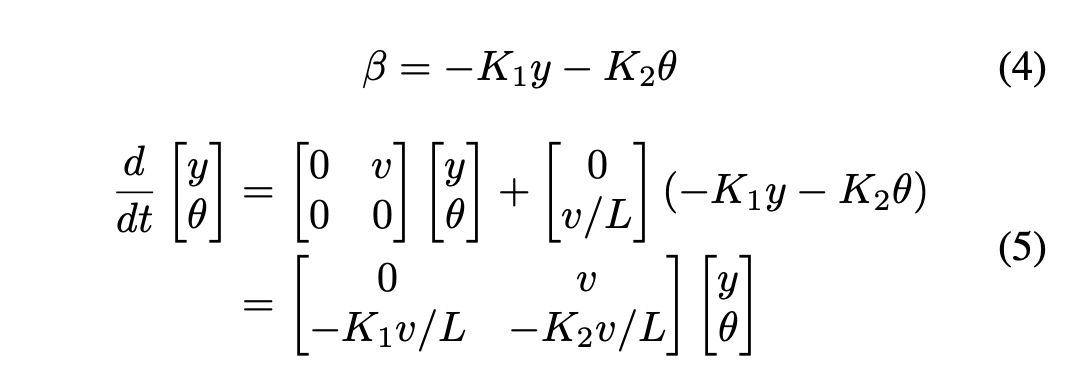
我们通过公式4建立横向控制,系统模型可由公式5描述。
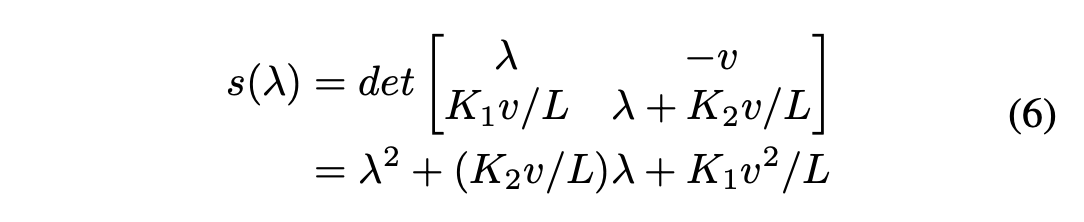
为了稳定系统,我们需要公式6中的行列式的所有根都有负实部。例如,让和,那么。
4. 基于深度强化学习的控制
在这一节中,我们试图应用深度强化学习的思想来训练一个用于停车控制的智能代理。为了实现这一目标,我们设计了一个基于虚拟雷达系统的强化学习环境,并探索奖励函数、观察空间和行动空间的选择。
4.1 深度强化学习
我们尝试使用自适应的DRL方法来解决这个控制问题。我们可以想象,停车场是一个静态环境。代理人感受到了当前的状态,并采取了行动来停放车辆。
一个标准的强化学习设置包括一个代理人在离散的决策纪元中与环境互动。在RL的每个决策步骤,代理观察到一个状态,采取一个行动并获得一个奖励。目标是找到一个政策,将状态映射到行动(确定性的)或行动的概率分布(随机性的),以最大化折现的累积奖励R_0=\sum_\{t=0}^\{T}\gamma^t r(s_t, a_t),其中是奖励函数,是代理人根据政策采取的行动,是折扣系数。有许多RL模型和算法,主要分为两类:基于价值(即Q-learning)和基于策略(即策略梯度)。
著名的 “演员批判 “模型结合了基于价值(即Q-learning)和基于策略(即策略梯度)。通过将感官处理的深度学习的进展与强化学习相结合,取得了重大进展,产生了 “深度Q网络”(DQN)算法[1]。
DQN不能直接应用于连续行为空间,因为它依赖于寻找使评价函数最大化的行为,在连续值的情况下,这需要在每一步迭代优化过程。[2]中的作者提供了一种无模型的、使用深度函数近似器的非政策性行为人批评算法,该算法可以在高维、连续行为空间中学习政策,即DDPG。在DDPG中,状态-行动策略根据批判性的DQN返回值函数被反复修改。使用链式规则,DQN的目标函数的参数梯度被转移到行为者政策网络中。Q值函数表示当代理人看到状态并在步骤采取行动时,对未来折现的累积奖励的期望。奖励的定义与类似。
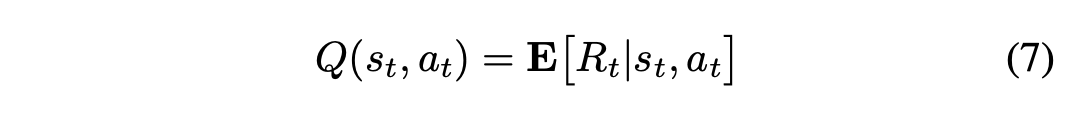
批评者的训练是为了最小化Q值网络的损失函数:
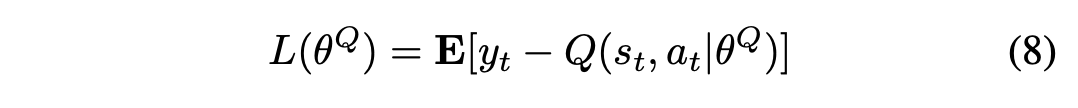
其中是DQN的权重参数,是目标值,可由另一个DQN,即目标网络,用公式9估计。
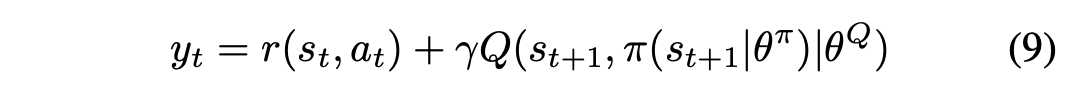
经验中继和目标网络被提出来以消除这个问题[3]。经验中继器将过去的状态动作对存储到一个重放缓冲器中,通过减少不稳定的参数训练或发散的风险而有利于训练。目标网络将在参数训练的缓慢演化过程中保持一个DQN。最后,在DDPG中,演员网络可以通过使用连锁规则来训练Q值函数J。
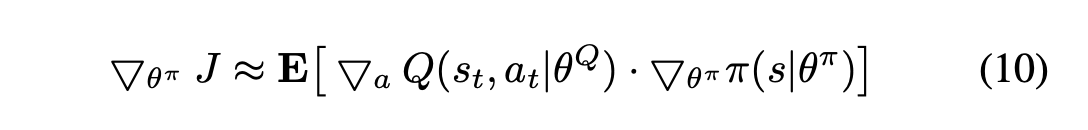
DDPG还利用经验回放和目标网络来确保训练的稳定性。
4.2 基于深度神经网络的DDPG算法
如图所示,一个DDPG网络通常由四个部分组成:环境、行为者网络、批评者网络和内存重放缓冲器。行为者网络由一个在线策略网络和一个目标策略网络组成。批评者网络由一个在线Q网络和一个目标Q网络组成。
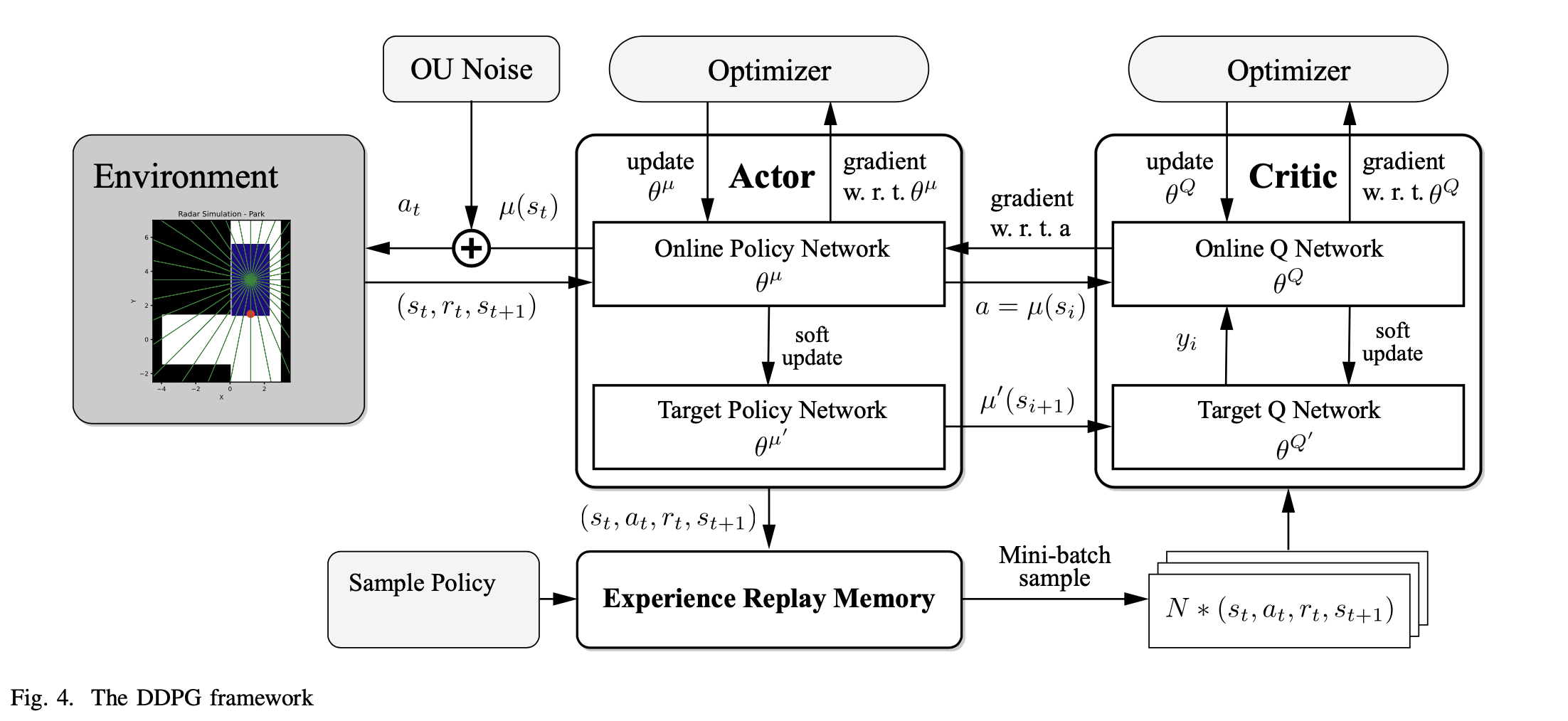
在线策略网络被用来适应策略函数。其参数被表示为\theta^\{\mu}。在训练中,我们通过Ornstein-Uhlenbeck过程(OU过程)向行动引入随机噪声。行动从确定性过程变为随机性过程,然后对行动进行采样并交给环境执行。
在线Q网络用于拟合Q函数Q^\{\mu}(s_t, a_t) Q网络生成链式规则下的行动梯度,并将其传递给在线策略网络进行训练。Q网络本身的参数是用随机梯度下降法(SGD)训练的。
目标政策网络和目标Q网络是在线政策网络和在线Q网络的副本。它们的参数通过下面描述的软更新算法进行更新。
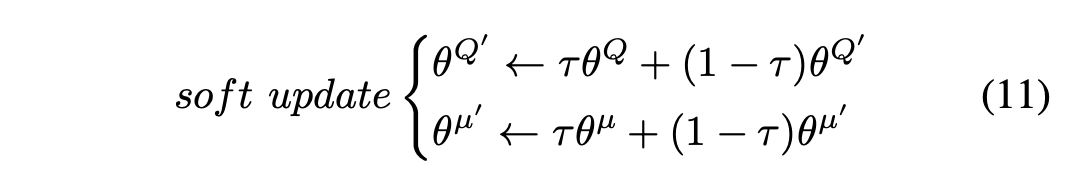
Replay Memory Buffer记录来自环境的状态转换数据(s_i, a_i, r_i, s_\{i+1}),并使用抽样策略生成样本,作为训练在线网络的数据集。
该算法的运行方式如下所示:

4.3 DRL中的停车位模拟器
1.综述:为了训练我们的代理,我们建立了一个专门的停车场模拟器。其Reset()方法重置车辆并返回环境状态,而Step()方法接受代理给出的行动,根据单轨自行车模式更新环境,计算奖励,并以四元数返回信息,其中表示代理是否已经解决了问题,表示调试信息。我们的停车场模拟器的设计主要是基于[7]。
2.观察设计:停车场模拟器的观察空间由以下部分组成。
- 当前车辆的状态 -
vehState - 当前车辆参考点与目标点之间的坐标差 (x_e, y_e) = (x_\{target} - x, y_\{target} - y)
- 当前车辆角度与目标角度的正弦和余弦之差 (\theta_e = θ_\{target} - θ)。
- 当前车辆的雷达读数 D_\{radar}
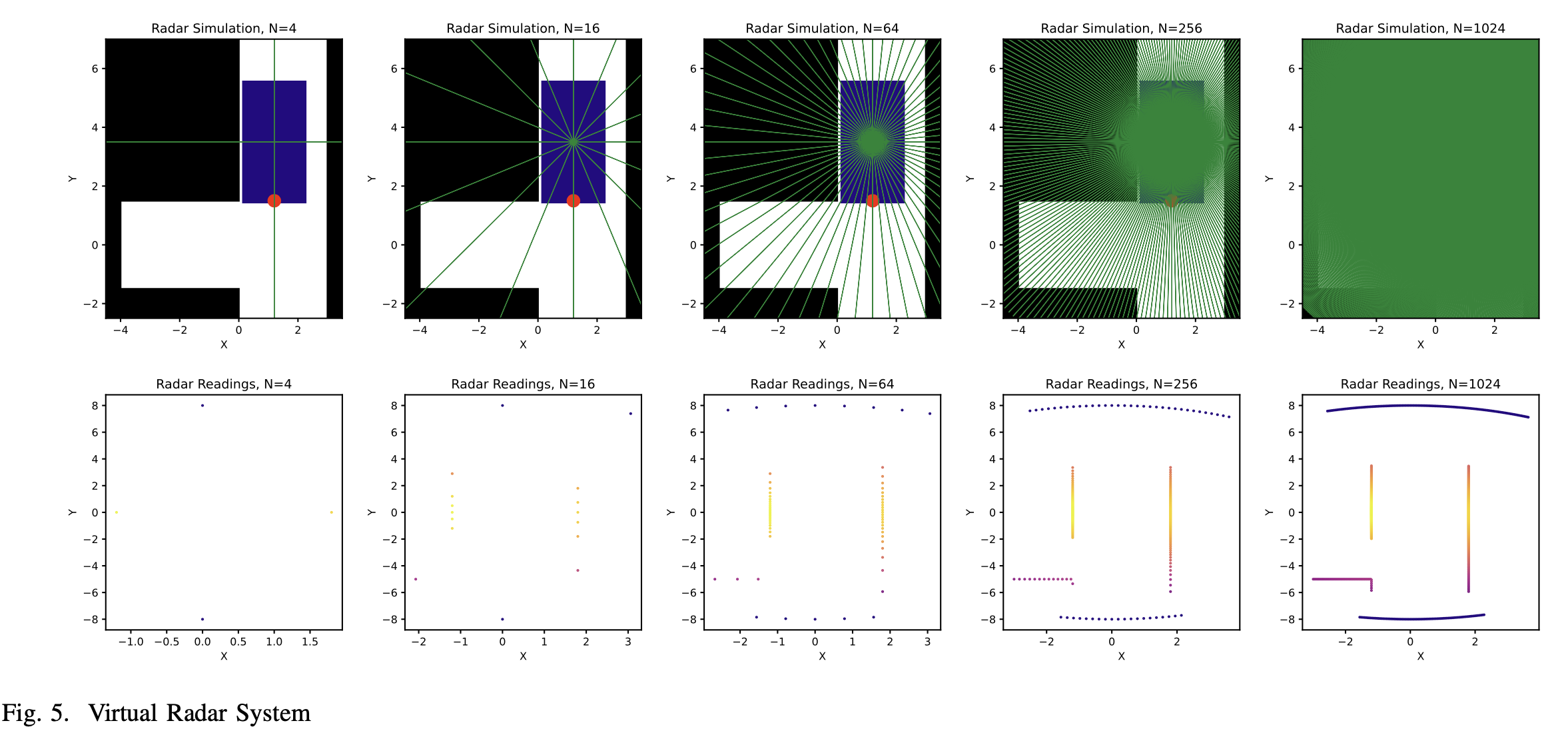
为了让智能体获得空间中的障碍物相对于车辆的距离,我们在车辆上添加了虚拟雷达。这些雷达是以车辆为中心的径向线。通过计算这些径向线与障碍物的交点,我们能够获得雷达读数。这些雷达的分辨率(雷达线的数量)可以调整,如图5所示。默认情况下,雷达线的数量是24条。
3.动作设计:我们的停车模拟器的输入是连续的目标转向角\beta_\{in}和速度v_\{in},其中\beta_\{in} \in ] -\pi /2, \pi/2 [,v_\{in} \in ]-1,1[。这是因为我们需要限制问题的探索空间。
4.4 奖励设计
奖励函数的设置是最重要的。一般来说,我们用不同的成分和比例系数来组成奖励函数。
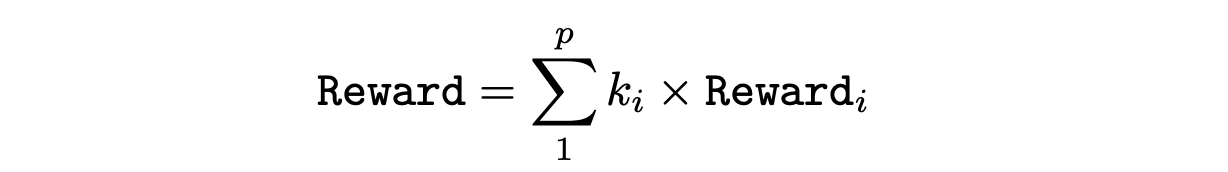
对于停车问题,我们对奖励函数的构成有如下选择。
- 对成功停车给予奖励
- 碰撞时给予惩罚
- 如果出界则给予惩罚
- 越来越接近目标位置的奖励
- 越来越接近目标角度的奖励
然而,并非每个项目都是必要的。因此,我们必须谨慎选择这些项目的量表系数。
4.5 行动者网络设计
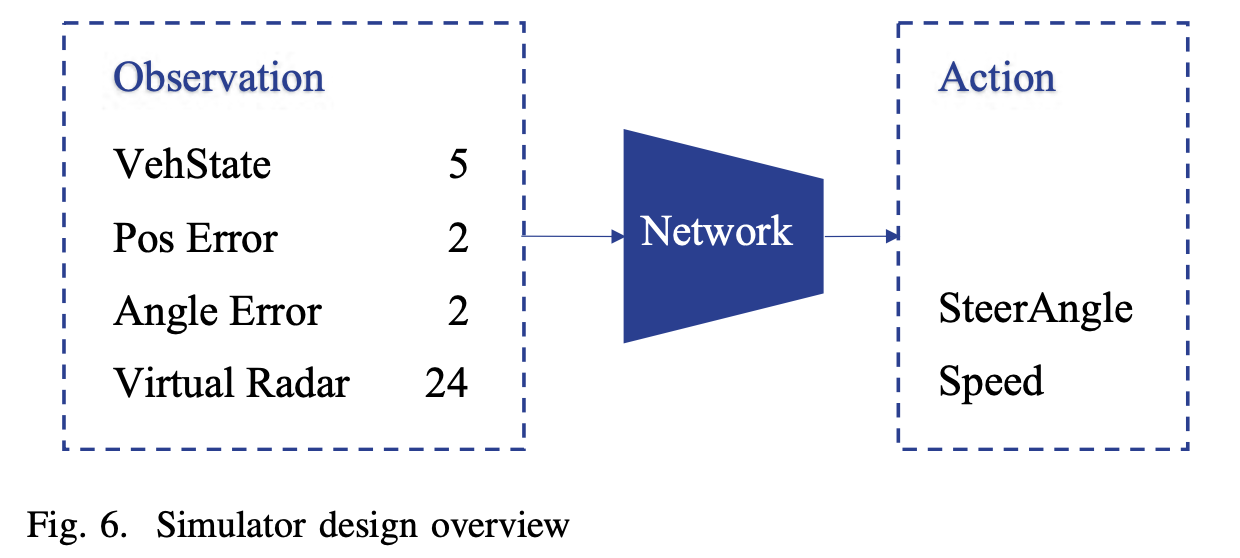
图6是行动者网络的设计概况。对于这样的输入,对于神经网络,我们只需要几层由ReLU函数激活的全连接的神经网络。特别要注意的是,神经网络的输出需要限制在-1和1之间,因为车辆的转向角和速度需要被限制。一个合适的方法是用函数来映射网络的输出
5. 实验及结果
5.1 混合控制
使用混合控制方法,我们已经成功地实现了窄空间停车。
从初始状态开始,我们使用经验规则基础的微调方法来完成第一阶段,并设定在开始第二阶段之前达到一个特定的角度。
在开始时,我们让模型在相同的时间长度后预测碰撞。在预测到碰撞后,它就会停止,并进入下一阶段。然而,这导致这种控制方法在特定位置或角度的收敛变得非常缓慢。在此基础上,我们应用了一种基于汽车位置的模型预测控制方法。例如,在左转过程中,对碰撞的预测条件不是很严格。我们减少了时间序列的长度。这增加了每个周期后模型收敛的速度。
在修改之前,为了达到进入第二阶段的条件,第一阶段的周期数达到200个左右。修改后,有可能达到47个循环后就可以使用第2阶段的位置和角度。这很好地提高了模型的收敛速度。车辆角度随控制轮次的变化如图7所示:
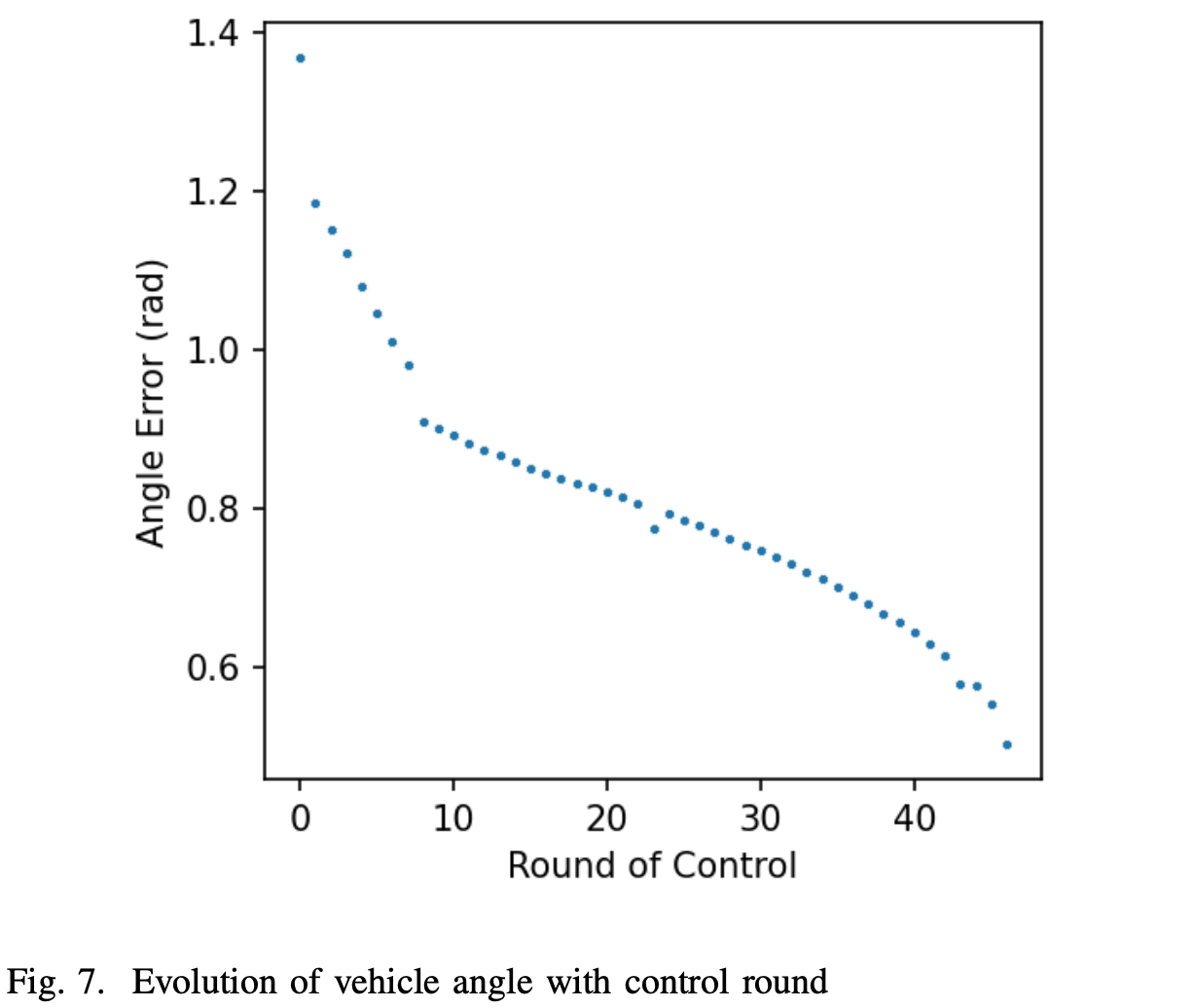
在实际操作中,我们将相变偏航角设置为0.5,以平衡收敛速度和可行性。
在第二阶段,如果我们直接使用瞬时微调方法,那么车辆会出现剧烈的横向摆动。因此,我们设定转向角只在向前移动时改变。通过使用这种方法,我们避免了汽车的剧烈摆动,我们可以在15个循环后完成停车。
5.2 深度强化学习
我们的DRL实验以失败告终。然而,在实验过程中,我们总结了一些困难和可能的解决方案:
- 环境的探索是非常困难的。由于实验环境中的无碰撞空间非常狭窄,智能体很容易与环境发生碰撞。因此,训练过程中不应将结束条件设定为碰撞,而应在碰撞发生时给予惩罚,同时允许小车部分落入墙壁,并在小车落入墙壁的过程中不断给予惩罚。
- 不适当的奖励功能会导致奇怪的智能体验行为。如果超时的惩罚没有设置或者太小,那么智能体就会选择静止不动直到超时,从而避免碰撞和出界的惩罚。如果越界惩罚太小,智能体将选择走最短的路径离开环境,从而结束这一轮探索。
- 来自虚拟雷达的信息是相对有限的。人类在使用双眼停车时,得到的视觉信息要丰富得多。雷达并没有覆盖所有的方向,因此可能导致智能体做出错误的决定。我们可以提高雷达的分辨率,或者使用在计算机视觉课程中学到的VR图像生成算法来渲染从车载摄像机视图中获得的停车场图像。
- 缺乏人的经验指导。由于环境探索的难度,代理人很难积累成功的经验。我们计划通过开发的游戏来导入人类经验。如图8所示,我们开发的互动游戏可以记录人类玩家完成停车任务的过程。我们可以尝试利用这些经验。
6. 总结
在这项工作中,我们将ASC方法应用于NSP任务,我们的混合控制策略仅在47个控制环后就成功了。在我们提出的混合控制成功的鼓舞下,我们进一步尝试用DRL方法来解决NSP任务。我们使用了一个虚拟雷达系统来模拟环境,建立了合适的奖惩机制,并采用深度神经网络来训练智能代理。不幸的是,我们的DRL尝试并不成功。
我们的成功让我们分享了智慧来自生活的启示。通过这项工作,我们意识到,传统的ASC方法在解决现实世界的问题上仍然有效和强大。尽管DRL方法在许多任务上表现出色,但由于缺乏领域专业知识,在一些需要专业知识的领域表现不佳。人工智能仍然是非常人工的,还有很长的路要走。
参考文献
[1] V. Mnih, et al., “Human-level control through deep reinforcement learning.” Nature, vol. 518, no. 7540, pp. 529–533, 2015.
[2] R. R. Afshar, Y. Zhang, M. Firat, U. Kaymak, “A State Aggregation Approach for Solving Knapsack Problem with Deep Reinforcement Learning.”, CoRR, arXiv, abs/2004.12117, pp. 1–17, 2020.
[3] Z. Xu, et al, “Experience-driven Networking: A Deep Reinforcement Learning based Approach.” in proceedings of the IEEE Conference on Computer Communications (INFOCOM), pp. 1871–1879, 2018.
[4] J. He and H. Li, “Fast A* Anchor Point based Path Planning for Narrow Space Parking,” in 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Sep. 2021, pp. 1604–1609. doi: 10.1109/ITSC48978.2021.9564837.
[5] C. Jang, C. Kim, S. Lee, S. Kim, S. Lee and M. Sunwoo, ”RePlannable Automated Parking System With a Standalone Around View Monitor for Narrow Parking Lots,” in IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 2, pp. 777-790, Feb. 2020, doi: 10.1109/TITS.2019.2891665.
[6] “Autonomous Parking Using Fuzzy Inference System - MATLAB & Simulink.” https://www.mathworks.com/help/fuzzy/autonomous-parking-using-fuzzy-inference-system.html (accessed Jan. 15, 2022).
[7] B. Thunyapoo, C. Ratchadakorntham, P. Siricharoen, and W. Susutti, “Self-Parking Car Simulation using Reinforcement Learning Approach for Moderate Complexity Parking Scenario,” in 2020 17th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), 2020, pp. 576–579. doi: 10.1109/ECTI-CON49241.2020.9158298.