基于上下文语言模型的机器阅读理解系统及优化
- 学生姓名:王金元
- 学生专业:信息工程(中法合作办学)-二专
- 指导教师:赵海
- 学院(系):上海交大-巴黎卓越工程师学院
- 时间:2021-06-30
第一章 综述
1.1 研究背景
在过去的几十年中,随着计算机算力的爆发式增长和计算机科学的飞速发展,人工智能从构想逐渐走向现实。作为人工智能领域的主要研究方向之一,自然语言处理(Natural Language Processing, NLP)旨在研究人与计算机之间用自然语言进行有效通信的理论和方法。自然语言处理主要分为自然语言理解(Natural Language Understanding, NLU)和自然语言生成(Natural Language Generating, NLG)两个阶段,前者要求计算机能够理解自然语言文本的含义,后者要求计算机在理解语义的基础上能够以自然语言来表达给定的意图和思想[1, 2]。目前,自然语言处理的主要应用有机器翻译、观点提取、问答系统、语音识别、文本分类、自动摘要和文本语义对比等。
机器阅读理解(Machine Reading Comprehension, MRC)不仅是自然语言理解的一项基本且长期的目标,更是一种全面的、综合的自然语言处理任务。早期的MRC任务被简化为要求系统返回包含正确答案的语句。当时的系统主要使用基于规则的启发式方法,例如词带方法和手动生成的规则[1]。近年来,MRC领域的研究取得了长足的进步,随着深度神经网络在NLP中的应用和注意力机制的引入,MRC任务进一步要求系统在NLU的基础上进行自然语言推理(Natural Language Inference, NLI)。在形式上,MRC旨在教导机器在理解特定段落的基础上,针对问题生成答案;在认知机理上,MRC要求系统在感知和理解的基础上进行决策;在处理技术上,MRC融合知识获取技术和语义分析技术,要求系统具备语意推理和语言生成能力。
1.2 任务介绍
常见的 MRC 任务分为四种:填空式,单选式,区间提取式和自由形式[1]。填空式是指将句子中的一个或若干个词进行遮罩,让模型从语料库中选出词来补充完整句子,代表性的数据集是CNN/DailyMail[16]。单选式是指将句子中的一个或若干个词进行遮罩,让模型从若干个选项中选出正确选项,代表的数据集有 RACE[13] 和 DREAM[15]。区间提取式是指给模型提供一篇文章和一个相关问题,让模型选择文章中的一个区间作为问题的答案,代表性的数据集有SQuAD1.0[12] 和 SQuAD2.0[11]。自由形式是指给模型提供一篇文章和一个相关问题,让模型从语料库中自行生成句子进行回答,代表性的数据集有 DROP[27] 和 CoQA[2, 14]。
为了加大模型推理的难度,部分数据集引入了不可回答的问题,要求模型在回答问题的同时对问题的可回答性做出判断,代表性的数据集有SQuAD2.0。
斯坦福问答数据集(Stanford Question Answering Dataset, SQuAD)是一项机器阅读理解的基础任务,由人群工作者在一组Wikipedia文章上提出的问题组成,其中每个问题的答案是对应段落中的一段文本或区间,或者该问题也可能无法回答[11]。现在有两个可用的版本,SQuAD 1.1 和 SQuAD 2.0。
提取式阅读理解系统通常可以在文章的上下文中找到问题的正确答案,但由于模型已事先假设在SQuAD1.1上的所有问题都可以回答,因此它们也往往做出不可靠的猜测。为了解决这一弱点,SQuAD的最新版本SQuAD 2.0于2018年发布,将现有的SQuAD数据与50,000个由人群工作者对抗性地写出的无法回答的问题相结合,看起来类似于可回答的问题。这些无法回答的问题经过精心设计,以致于它们不但与该段落相关,并且该段落包含一个该问题所要求的类型相同的看似合理的答案[11]。为了在 SQuAD 2.0 上取得出色的成绩,MRC系统不仅要学会根据文章内容通过理解和推理找出正确答案,还需要判断问题是否可回答,在不可回答时明智地放弃回答[3]。
1.3 标准阅读理解系统
受认知心理学的双重过程理论启发,人脑的认知过程可能涉及两种不同类型的过程:情景化感知和分析性认知,其中前者在隐式过程中收集信息,可以被具象为“阅读”过程,后者进行推理和决策执行,可以被具象为“理解”过程。基于上述理论基础,解决MRC问题的标准阅读系统通常由两个模块组成:深度预训练语言模型作为编码器,根据任务特征设计巧妙的机制作为解码器[1]。
编码器的作用是将自然语言文本投影到向量空间,并进一步对整个序列的上下文特征进行建模。编码器需要提取多粒度语言特征,例如词级语言特征、句级语言特征和段集语言特征;同时,编码器还需要识别语句中的显著特征,例如命名实体、句法结构和词性。最近的研究表明,对结构性的人类知识进行建模能够显著提升编码器对于人类语言知识和世界常识的理解能力[1, 2, 3-10]。早期,递归神经网络(Recurrent Neural Network, RNN)被视为序列建模或者语言模型重的最佳选择,因此传统的编码器主要由长短期记忆网络(Long Short-Term Memory, LSTM)[17]和门循环单元(Gated Recurrent Unit, GRU)[18]构成。然而,递归架构存在致命的缺陷:在训练过程中无法并行执行,从而极大限制了计算效率[1]。Vaswani等人提出了Transformer模型,它基于注意力机制,既能够实现并行计算,也能够捕获任何跨度的语义相关性,因此越来越多的语言模型倾向于选择它作为特征提取器[19]。
解码器的作用是将向量空间的隐态进行处理,投影到特定任务要求的输出空间。在对输入序列进行编码之后,解码器将针对特定任务的要求,使用上下文表征的序列表示来解决问题。比如,解码器的结果可以为选择题的预测选项,也可以为在原文中预测的答案区间。直到最近,几乎所有的MRC系统都将重点放在编码器方面,因为这些系统能够简单而直接地受益于足够强大的编码器[1]。然而,近期的一些工作表明,更好的解码器或者更好使用编码器的方式仍然能对MRC性能有重大影响[3]。值得一提的是,尽管更强大的编码器和更好的解码器对于模型的性能都有显著提升,解码器端的设计却鲜有人关注[1]。
1.4 上下文语言模型
2018年,Peters等人提出ELMo模型,被称为深度上下文化的词表示方法[20]。与最广泛使用的词嵌入不同,ELMo词表示是基于整个输入句子的表示,也被称作上下文化的词表示方法。这种表示方法能够根据上下文的语言环境动态地生成词表示。此后的BERT[5]模型及其衍生模型也使用了这种上下文化的词表示方法,因此和ELMo被统称为上下文语言模型(Contextualized Language Model, CLM)[1]。目前主流的上下文语言模型还包括GPT-1[4]、XLNet[21]、RoBERTa[7]、ALBERT[6]、ELECTRA[8]、DeBERTa[10]等。
目前,基于Transformer的CLM主要可分为单向模型和双向模型[4, 5]。单向模型沿语句的正序方向进行建模,仅能捕捉后方语句成分对前方语句成分的语义关系和依存关系;双向模型沿语句的正序和反序方向进行建模,能够捕捉任意语句成分之间的语义关系和依存关系。OpenAI实验室提出的GPT(Generative Pre-Training)系列模型是典型的单向Transformer模型[4]。由于单向模型只能捕捉单向语义依存关系,GPT系列模型需要使用更多的参数和更大的模型尺寸来进行学习。尽管GPT系列模型在部分自然语言处理任务中取得了不错的成绩,但是它的缺点是模型参数量巨大,训练语料库巨大,训练成本巨大,这为该模型的应用设置了极高的计算资源门槛。2018年由Google提出的BERT(Bidirectional Encoder Representations from Transformers)模型是典型的双向Transformer模型,它使用了12层Transformer模型,在11项NLP任务上达到了最好的表现[5]。从那时起,BERT模型和其衍生模型在著名的MRC任务SQuAD的排行榜上高居榜首。
在 2019 年,全面的网络预培训在语言表示学习方面取得了一系列突破。但是,由于GPU/TPU内存的限制和较长的训练时间,增加模型大小给预训练过程带来了很大的困难。为了解决这些问题,Google推出了一个轻量级的BERT模型,叫做ALBERT(A Lite BERT),用于语言的自监督学习[6]。与原始BERT模型相比,需要学习的参数更少,ALBERT 模型在基准测试中甚至具有更好的性能。
RoBERTa (Robustly Optimized BERT)是一种基于 BERT 模型的鲁棒训练方法,它基于BERT并修改了关键的超参数,消除了下一句预测(Next Sentence Prediction, NSP)的预训练目标,并以更大的训练批次和学习率进行了训练,达到了最先进的结果[7]。
2020 年,斯坦福大学和 Google 引入强化学习的方法,提出了一种新的预训练方法,叫做 ELECTRA。它需要训练两个基于Transformer的模型,一个叫做生成器,一个叫做鉴别器。生成器是一个屏蔽语言模型(Masked Language Model, MLM),它的作用是替换序列中的令牌;鉴别器是我们要训练的模型,它需要确定序列中的哪些令牌被替换过了[8]。
与此同时,关于Transformer模型的研究也从未停止过。2019年,Dai等人发现Transformer模型具有学习长期依赖关系的潜力,但在语言建模的设置中受固定长度上下文的限制。因此,他们提出了一种新颖的神经体系结构Transformer-XL,它引入了新的位置编码方案,能够使学习依赖关系超出固定长度,在捕获长期依存关系,又不会破坏时间连贯性。XLNet模型是Transformer-XL模型的扩展,该模型使用自回归方法进行预训练,以通过在输入序列分解阶数的所有排列上最大化预期的似然性来学习双向上下文[9]。
目前,最先进的MRC系统之一是DeBERTa(Decoding-enhanced BERT with Disentangled Attention)模型,它在RoBERTa模型的基础上引入了“解缠绕注意力”机制和“遮罩增强”训练方法,只用了RoBERTa模型一半的训练数据,在SuperGLUE排行榜上取得了第一名的成绩[10]。
1.5 预训练和微调
传统的机器学习和深度学习的训练模式为:用户自主搭建全部的模型,独立完成模型训练。由于MRC系统模型参数量往往巨大,需要大量的计算资源,普通用户往往难以实现模型训练。
2018年以来,预训练语言模型成为NLP领域的新的范式:具备计算资源的中心节点完成一般化的语言模型的大规模预训练,提供接近完成的模型模块;用户节点借用预训练模模型作为标准化模块搭建完整模型,在所提供的预训练基础上针对特定下游任务进行微调。
1.6 选题动机
单选式阅读理解任务要求模型在若干个选项中选出正确的选项,因此较为容易对模型的输出和标准答案进行比对,从而对MRC系统的表现给出客观的评价。不同于单选式任务,抽取式阅读理解任务类似于开放性问答,目前主流的评价指标为EM(Exact Match)分数和F1分数,EM分数反映预测答案和标准答案是否完全匹配,F1分数反映预测答案和标准答案的匹配程度。模型的预测可能与标准答案并不完全一样,但在语义上是正确的。这类问题即使是人类进行回答,也会由于个人回答问题风格的差异,做出与标准答案不尽相同却大意正确的回答。
在对于模型输出和标准数据集的对比中,我们发现现有的MRC已经能够较好地进行机器阅读和语意推理,然而,模型给出的答案在形式上并不完全正确。从图1-1的例子中我们不难发现,实验中的MRC系统能够较好地理解文章和问题,并给出语义上正确的答案。但是,根据MRC常用的评估方式,该答案没有完全匹配标准答案,因此EM得分为0,F1得分为0.5. 对于上例,尽管MRC系统给出了接近完美的回答,但是得分表明这是一个较为差劲的回答。因此,我们认为这样的得分无法很好表现模型的阅读理解和语义推理能力,在现有的评估体系下,MRC系统的性能很可能并没有被充分发挥出来。

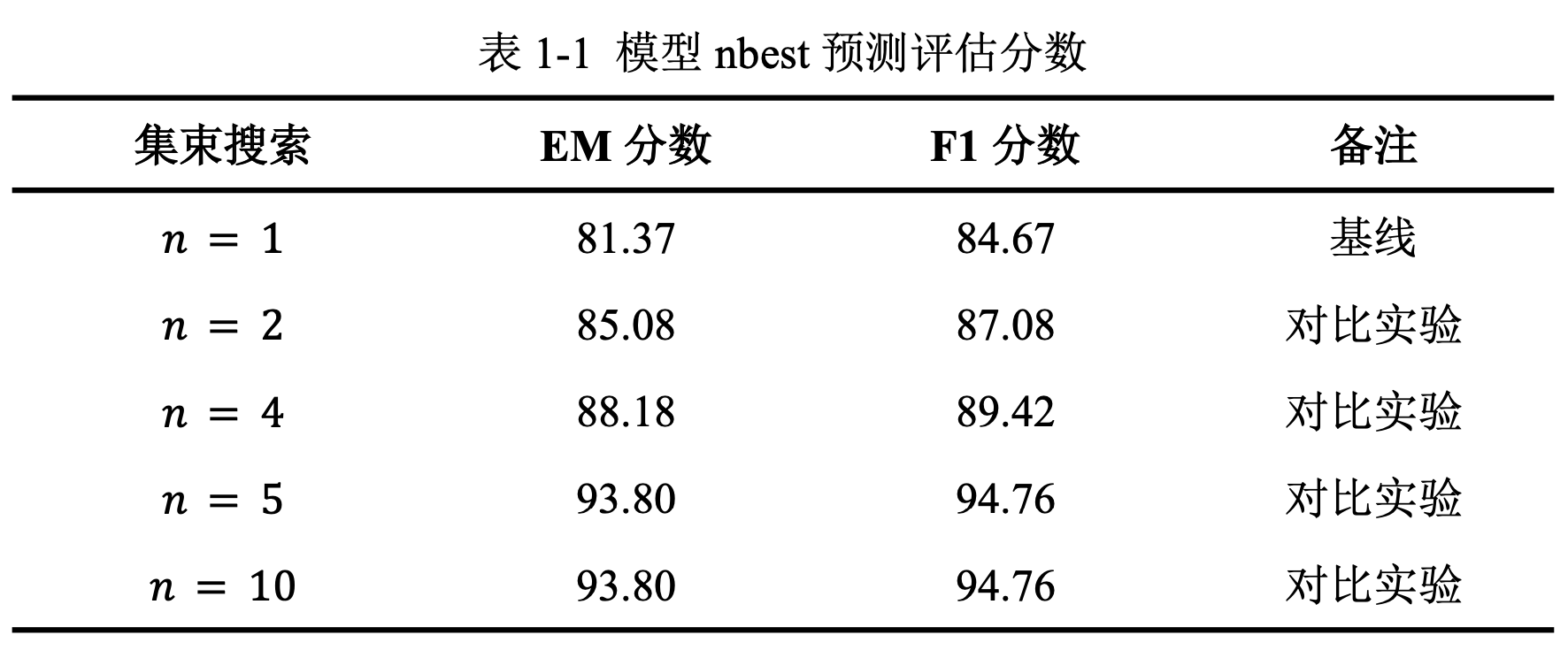
在初步的实验中,我们采用集束搜索(Beam Search)算法,让该系统针对每一个问题选出最好的个答案,并进行输出。在评估过程中,对于每个问题,在不改变答案的前提下,我们选择这个答案中最高EM得分的答案作为模型的最终输出。默认的评估方式是选择模型对每个问题的概率最高的回答作为最终输出,相当于我们实验中的情况。
如表1-1所示,我们发现得分最高的答案并不总MRC系统输出的最高概率的答案,得分最高的答案很可能在模型输出的最好的五个答案中。类比于人类阅读理解时根据标准答案学习回答的技巧,借鉴单选式MRC任务形式,我们希望MRC系统能够根据特定数据集答案的风格,在阅读器输出的最好的四个答案中选择出得分最高的答案。更进一步,我们希望解码器能够学习特定数据集的标准答案风格,输出符合标准答案形式和风格的答案。
在本文中,我们将搭建一个基于深度预训练CLM的阅读理解系统,研究编码器和解码器对模型性能的影响。我们将提出一种新型解码器架构,配合现有的基于深度预训练CLM的编码器,在SQuAD2.0数据集上进行微调和评估。
第二章 相关工作
在本章节中,我们将简要介绍和本工作相关的前人的研究发现和实验成果。近年来,为了显著提升MRC系统对于抽取式任务的表现,有的工作聚焦于针对任务特征的解码器架构设计,有的工作致力于提出答案纠正的通用型解决方案,有的工作提出了创新性地数据增强策略来增强模型的训练效果,此外还有一些工作针对选择式任务的创新性工作。
2.1 多模块问答系统
受人类如何解决阅读理解问题的启发,2020 年Zhang等人基于ALBERT提出了一种回顾性阅读器系统(Retro-Reader)[3]。该系统整合了阅读和验证策略的两个阶段:(1)粗略阅读,简要研究段落和问题的整体相互作用,并做出初步判断;(2)精读以验证答案并给出最终预测。Retro-Reader 模型使用ALBERT预训练模型作为编码器,自定义的解码器在SQuAD2.0任务中表现优异,霸占排行榜榜首长达九个月[3]。
该系统启发性地将SQuAD2.0任务分为两个主要问题:判断问题可回答性的二分类问题和寻找答案区间的问答问题。在代码实现上,Retro-Reader由一个二分类模型、一个问答模型和一个验证器组成。两个模型分别用ALBERT预训练模型作为编码器,搭配上简单的解码器,验证器将两个模型的输出进行组合输出得到最终的输出。
该系统的多模块化设计能够有针对性地解决SQuAD2.0数据集的多个细分任务,每个模块只需要关注一个细分任务,降低了任务对每个模型的要求。模块化的设计能够在输出的时候对多个模块的输出进行加权处理,以达到最优的效果,从这个意义上来看,多模块化设计的单模型和单模块设计的集成模型的思路并不相同。
2.2 答案区间修正
2020年,Reddy等人发现:对于可回答的问题,现有的MRC系统倾向于产生部分正确的答案,而不是完全正确的答案,因此模型预测结果的EM分数和F1分数之间总是存在不小的差距[22]。因此,作者提出了一个答案区间修正系统,由阅读器和修改器构成。该系统同样采用多模块化的设计,阅读器用于生成预测的答案,修改器将阅读器生成的答案放入原文中进行答案区间边界的调整,使最终输出的答案区间更加接近真实的答案区间[22]。
2.3 平滑标签学习
2020年,Zhao等人[23]认为:在抽取式任务的训练过程中,标准交叉熵损失的使用仅允许模型考虑一个正确答案,而忽略其他候选答案,因此模型会将其他语义正确但和正确答案不同的“可接受的”答案认为是错误答案。
Zhao等人提出了平滑标签学习的数据增强方式,借助标签平滑化、单词重叠和预测分布的策略,让模型能够更好学习到正确答案和语义相近的答案的分布,显著提升MRC系统在多个抽取式数据集上的表现[23]。
2.4 选项对比网络
2019年,Ran等人发现:在处理多项选择阅读理解问题的时候,人们通常在详细阅读文章之前先在多个粒度级别上比较选项,以使推理更加有效[24]。为了模仿人类答题技巧,Ran等人提出了一个选项比较网络(Option Comparison Network, OCN),该网络可以在单词级别对选项进行比较,以更好地识别他们之间的相关性以帮助推理。该模型将每个选项编码为向量序列,以尽可能保留细粒度的信息,并利用注意力机制逐个比较这些序列,以识别选项之间更细微的相关性[24]。在人类英语考试数据集RACE上的实验结果表明,该模型对于处理多项选择任务具有明显的效果。
第三章 实验设计
在本章节中,我们将介绍我们实验的主要情况,包括系统设计、数据处理和实验设置。在本实验中,我们选用SQuAD2.0作为标准任务数据集,来研究和评估MRC系统的性能。模型方面,我们选用HuggingFace提供的最新的自然语言处理工具包Transformers[25]以及基于Python的深度学习库PyTorch[26]。
3.1 系统设计
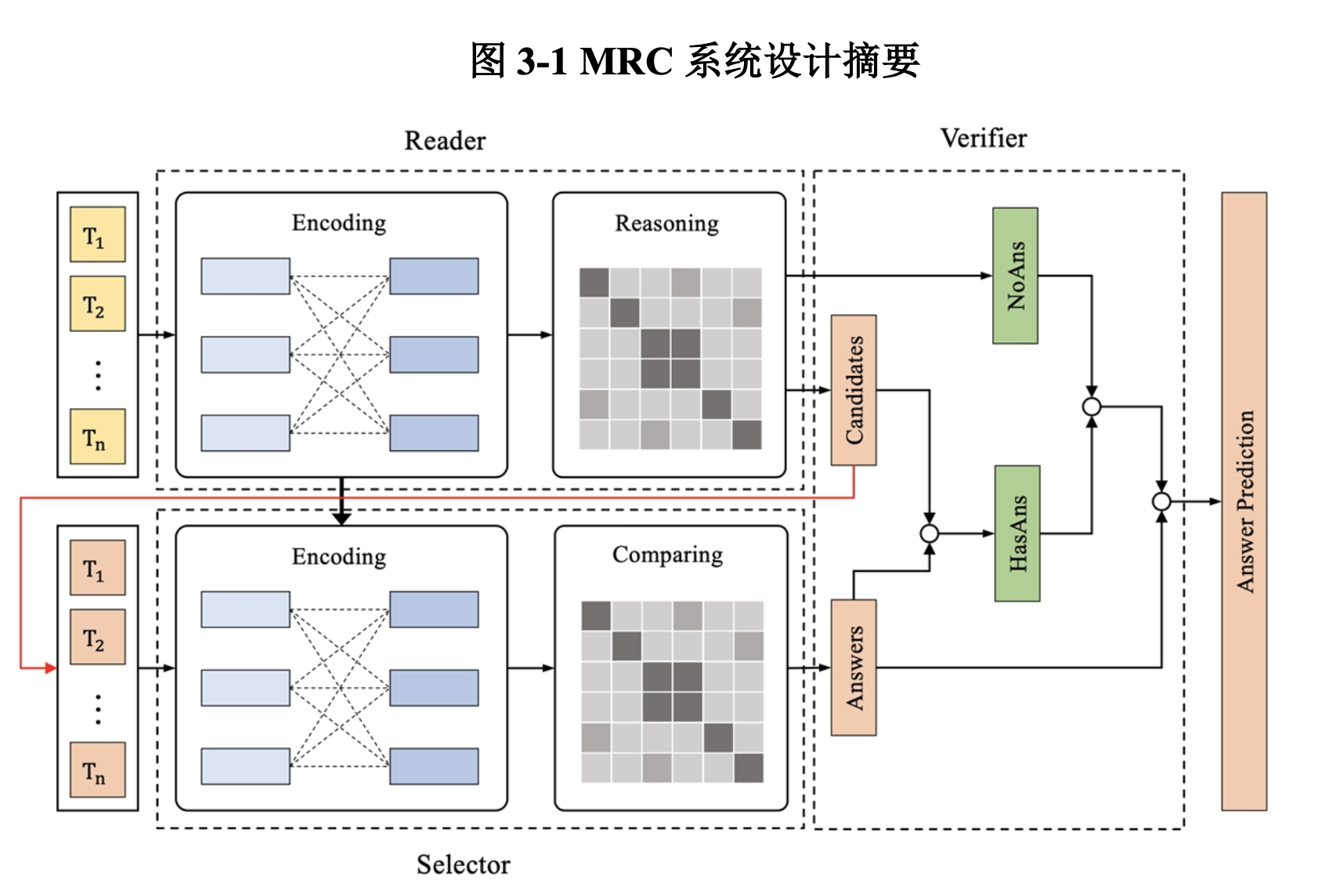
如图3-1,我们的多模块化MRC系统由阅读器、选择器和验证器组成:阅读器用于针对给定的文章和问题进行理解和推理,返回原文中包含答案的区间;选择器用于将阅读器对于每个问题的个最好的输出进行重新排序,选择最符合当前数据集正确答案风格的答案;验证器用于结合阅读器和选择器的输出,寻找最佳参数并得到模型的最终输出。
3.1.1 阅读器
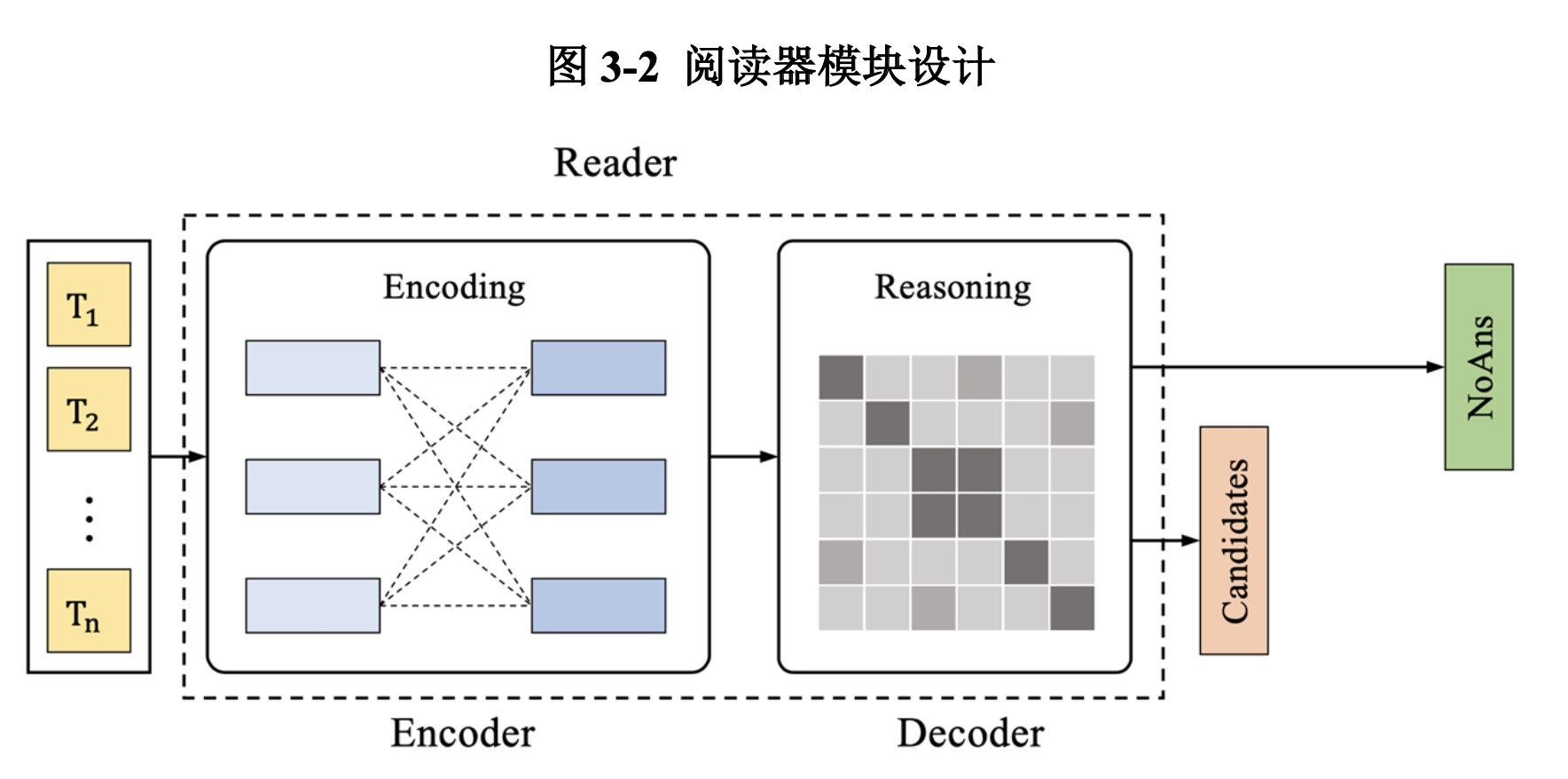
阅读器的任务为改进型的区间提取式MRC任务,阅读器需要根据输入进行理解和推理,返回正确答案所在原文区间的起点位置和终点位置,我们将无法回答的问题定义为答案区间的起点位置与终点位置重合。如图3-2,阅读器采用主流的编码器-解码器设计:编码器由深度预训练CLM构成,解码器由一层全联接网络构成。在Transformers模型针对问答任务的经典设计基础上,我们针对SQuAD2.0数据集新加入的“可回答性”特性,在训练阅读器的中加入了关于“可回答性”的损失[3]。
阅读器需要经历两个阶段:训练和评估。在训练过程中,我们用标准交叉熵损失来处理区间起点、区间终点和可回答性的预测。在模型评估过程中,我们使用集束搜索算法,让系统针对每一个问题选出最高概率的个答案,输出为dev-nbest文件。在模型训练完成之后,我们要求系统在训练集上进行一次评估,产生的train-nbest文件用于后续选择器的训练。
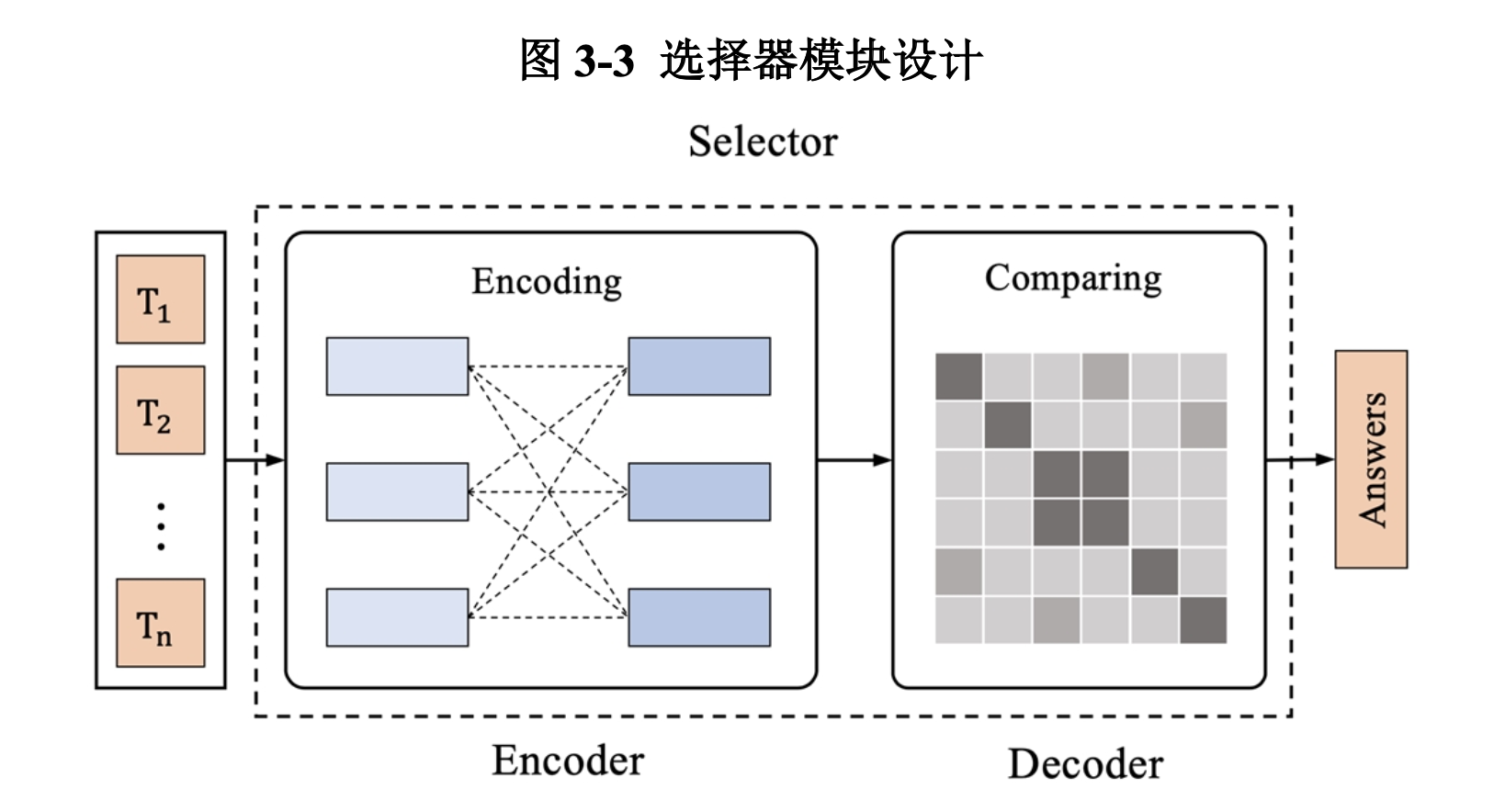
3.1.2 选择器
我们将选择器的任务定义为标准的多选式MRC任务,选择器需要在四个选项中选出回答风格最接近数据集正确答案的选项。如图3-3,选择器同样采用编码器-解码器架构:我们使用经过微调训练的阅读器的CLM作为选择器的编码器,解码器为选项对比网络。
选择器需要经历三个阶段:训练、评估和预测。在训练过程中,我们固定编码器的所有参数,只对解码器中的参数进行训练,并使用标准交叉熵损失来处理模型预测。在评估过程中,我们选择准确率作为选择器性能的评价指标。我们使用SoftMax函数将模型的输出转化为四个选项的概率,再通过Argmax函数得到模型的选择,与标签进行比较。我们选择评估阶段准确率最高的检查点模型进行预测,在预测过程中,选择器模型将对每个选项进行打分。经过SoftMax函数之后,每个选项的分数将变为相应的概率,并进行输出。
3.1.3 验证器
验证器的作用是将阅读器和选择器进行组合输出。如图3-4,验证器将结合阅读器和选择器的输出进行可回答性判断,并选出最合适的答案。对于问题,假设阅读器给出的概率最高的四个答案分别为[, , , ],他们对应的概率分别为[, , , ],那么最终每个选项的得分由两组概率经过加权后得到:
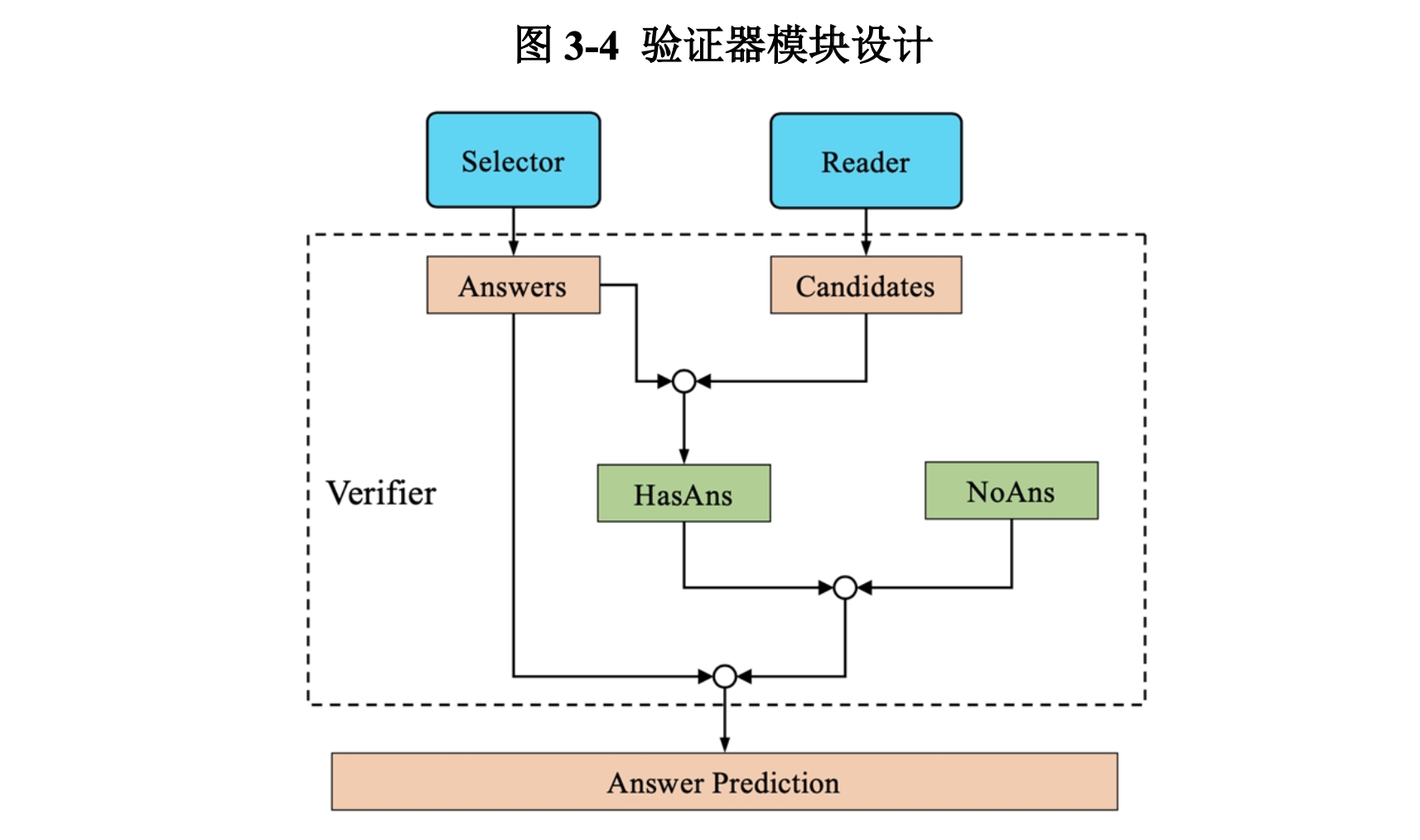
对于可回答性,我们使用Sigmoid函数将阅读器中的[CLS]令牌分数转化为概率,再加上阅读器的前四个输出中空字符串对应的概率(若不存在空字符串则概率为0),求均值后得到问题不可回答的分数。我们选择得分最高的选项的分数作为问题可回答的分数。若,则该问题无法回答,系统返回空字符串作为答案;否则,系统将分数最高的选项作为答案。
3.2 数据处理
阅读器的数据集为标准的SQuAD2.0数据集。
在阅读器训练完成之后,我们要求阅读器在训练集上进行一次评估,产生的train-nbest文件用于选择器的训练。对于SQuAD2.0的训练集中的每个问题,我们将每个正确答案和train-nbest文件中的三个最高概率非正确的答案组成一道多选题;同理,选择器的验证集由SQuAD2.0的验证集和阅读器的dev-nbest文件组合产生。在选择器做预测的时候,对于测试集中的每个问题,我们从阅读器最好的检查点的nbest输出中选择概率最高的四个答案,作为选择器的输入。
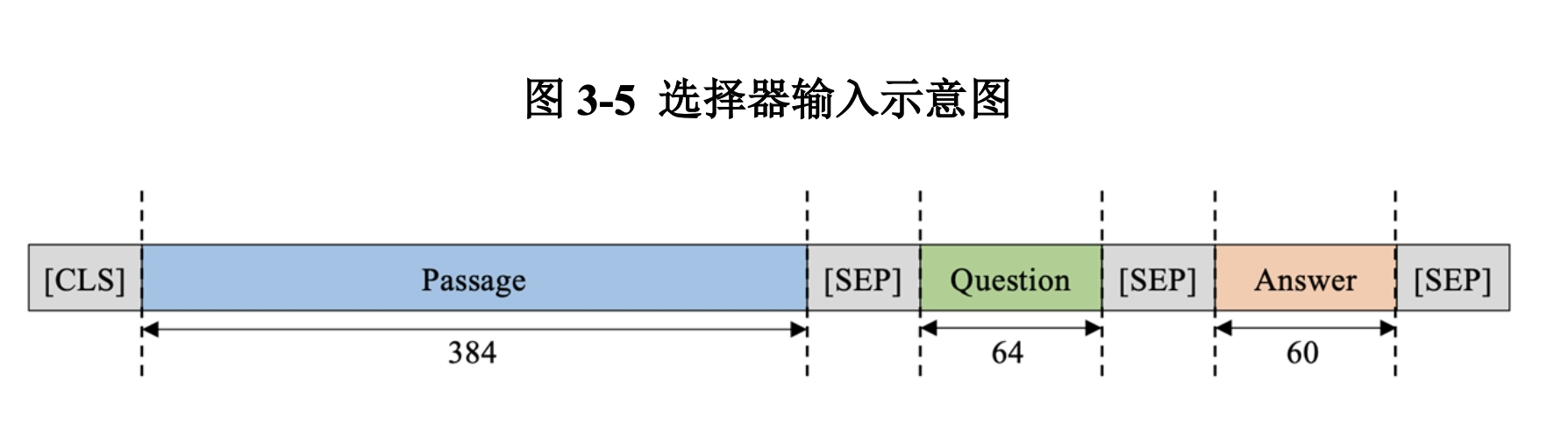
如图3-5,对于每一道多选题,我们将文章、问题和答案合并到一起进行上下文语言表征,得到四个语言表征。其中,文章和问题的令牌标签为0,答案的令牌标签为1,用于使模型明白输入的语言表征的不同成分。经过数据集特征分析之后,我们选择文章最大长度为384,问题最大长度为64,答案最大长度为60,加上4个特殊令牌,每个上下文语言表征的长度为512,长度不够的成分使用[SEP]令牌来补全(padding)到最大长度。
值得一提的是,习惯上令牌的补全一般使用[PAD]令牌,然而,选项对比网络的原始代码中使用的是[SEP]令牌[24]。经过实验验证之后,我们发现使用两种令牌做补全的效果没有明显,可认为是等效的。
3.3 实验设置
在本实验中,我们设置六个实验组:我们选择深度预训练上下文语言模型BERT,ALBERT和DeBERTa各自的base型号和large型号作为基线模型。我们将使用相应预训练模型的MRC系统作为对照模型。
本实验中所有的预训练语言模型的都来自Transformers工具包[25]。模型训练方面,我们使用16块GTX 1080Ti GPU和8块Tesla P40 GPU,每8块GPU一组来对预训练模型进行微调。
在实验中,我们希望观察到:
-
加入答案验证机制的阅读器模型相较基线模型性能有显著提升。
-
对于我们提出的MRC系统,更强大的CLM将带来更好的系统性能。
-
我们提出的MRC系统相较于前人提出的优秀的MRC系统有更好的性能。
-
我们引入的选择器能够较准确地选择出与标准答案风格一致的备选答案,从而提高系统预测的EM分数。
第四章 结果及分析
在本章节中,我们将展示实验结果并对实验结果做出合理分析。
4.1 实验结果
4.1.1 答案验证机制
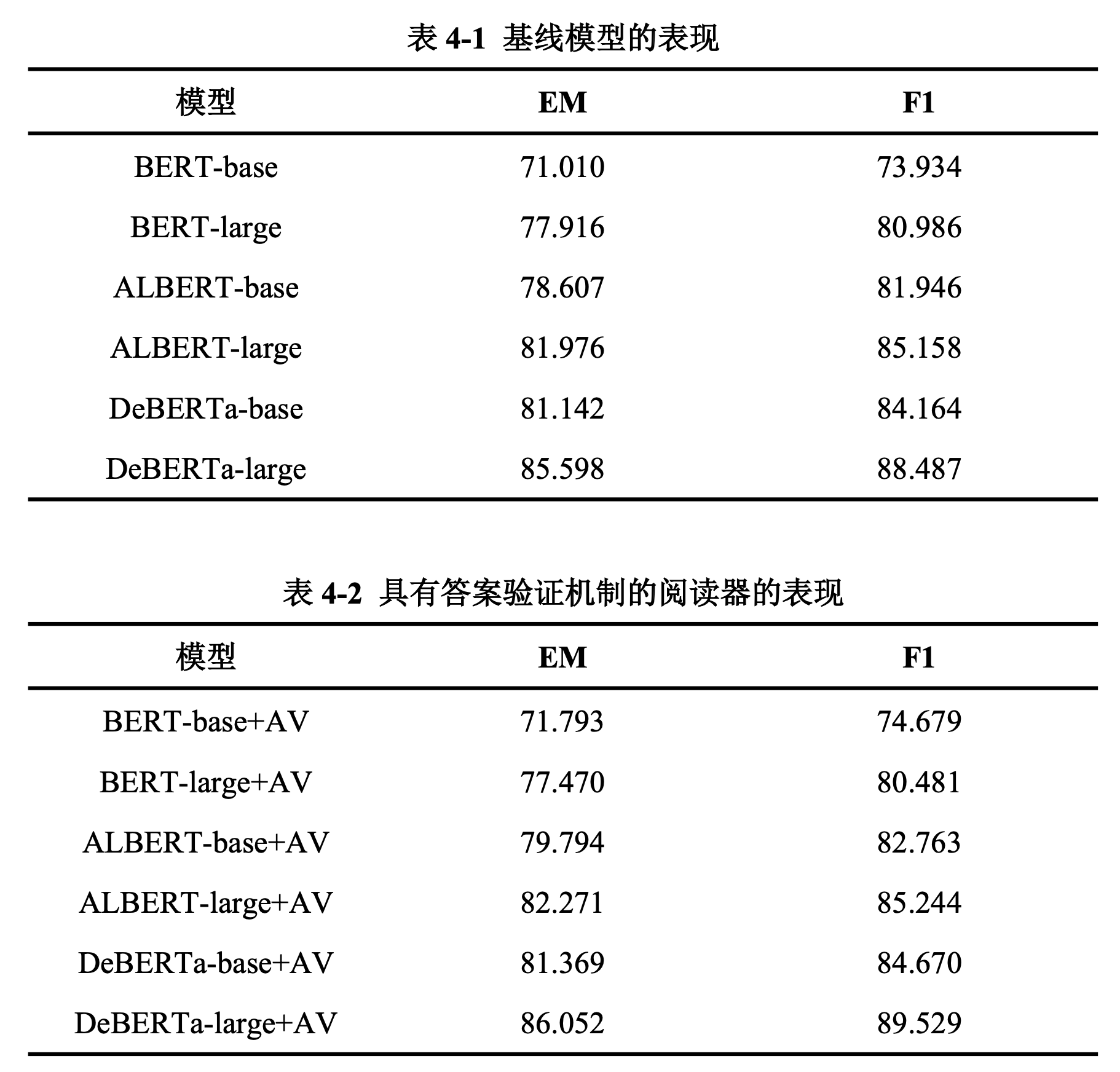
对比表4-1和表4-2,我们发现,答案验证机制能够显著提升阅读器的性能。在我们的六组实验中,答案验证机制使系统在EM分数上的提升为0.5-0.7分,在F1分数上的提升为0.5-1.0分.
4.1.2 具备选择器的MRC系统
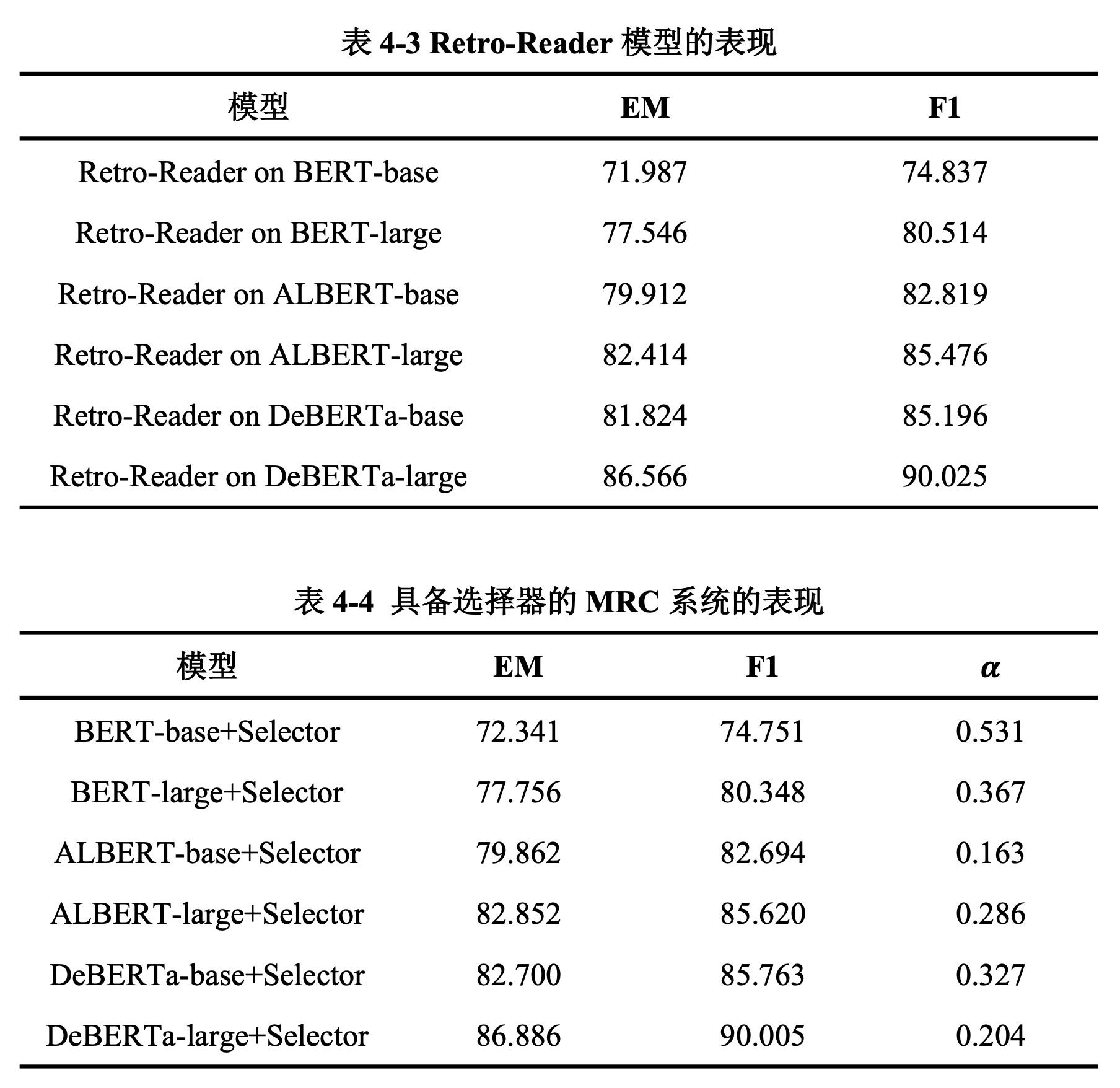
对比表4-3和表4-4,我们发现我们提出的具有选择器的MRC系统的表现明显超过了前人优秀的Retro-Reader系统:我们的系统在EM分数上提升0.3分左右,在F1分数上几乎保持持平,这和我们的选题动机是一致的,也表明我们的系统设计是合理的。
由表4-4可知,随着深度预训练CLM性能的增强,我们提出的具备选择器的MRC系统的表现也有显著提升。
4.2 结果分析
4.2.1 消融实验
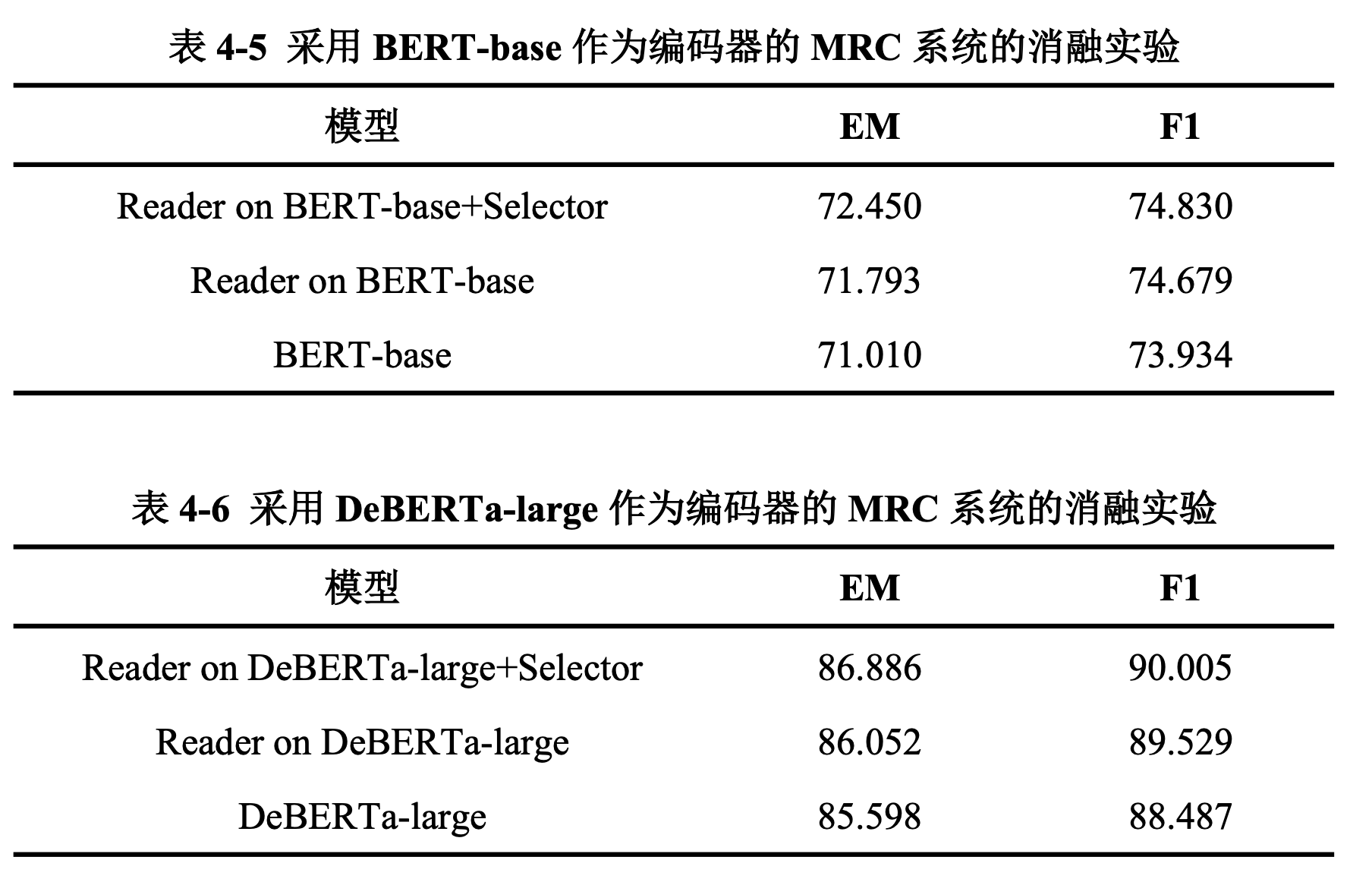
从表4-5和表4-6中,我们可以观察到:无论编码器使用的CLM性能强大与否,训练过程中答案验证机制的加入能够显著提升阅读器的性能,选择器的加入能够进一步提升MRC系统的表现,缩小EM和F1之间的差距。
4.2.2 模型分析
在公式(2-1)中我们引入了选择器预测结果的权重参数,我们通过网格搜索法(Grid Search)寻找系统到最佳的参数。根据表4-4,我们发现对于我们提出的具备选择器的MRC系统,编码器的预训练CLM越强大,选择器预测结果对于最终预测结果的权重越小。
这种情况在一定程度上符合我们的预期:一方面,随着编码器性能的提升,具备答案验证机制的阅读器已经能够较好理解问题,并给出接近完美的回答,仅依靠阅读器的输出就能够得到较好的成绩,因此相对来说选择器的预测结果的权重将会降低。另一方面,这样的结果也表明我们的选择器并没有能够很好区分四个选项,从而无法给出较为有效的预测。
在系统评估的过程中,我们确实发现:无论编码器的性能如何,选择器的准确率在提升至75%左右的时候会遇到瓶颈,无法继续提升。我们进一步研究并分析选择器性能瓶颈的原因:
-
从输入语义上看,每个问题的四个选项可能较为相似。在生成选择器的训练数据集的时候,我们直接让训练好的阅读器在训练集上进行评估,由于阅读器已经在训练集上进行了数轮微调,因此阅读器非常容易给出完全正确的答案或者与正确答案非常接近的语义正确的答案。然而,在产生数据集的时候,我们是从SQuAD标准训练集上采集正确选项,从train-nbest中采集错误选项。尽管我们已经将
train-nbest中的正确答案剔除,但是其余的错误选项很可能是语义正确但与正确答案在形式上不尽相同的预测。因此,四个选项在经过基于上下文的词嵌入之后的语言表征将会非常相似,四个选项在模型的隐式空间内的分布也将会非常接近。由于编码器是从语言表征中提取语义信息和句法信息,选择器模型将会很难在隐式空间中有效区分四个选项的语言表征。 -
从输入内容上看,每个问题的四个选项差异可能较不明显。在3.2节中我们介绍过,四个选项的输入是由文章、问题和备选答案拼接而成。对于一个问题,四个选项的文章和问题都是相同的,只有备选答案在内容存在不同,加之文章和问题所占的比例较大,因此四个选项的内容差异不大。编码器进行编码的时候主要注重语义和句法结构的提取,可能无法对这些内容上的细微差异进行放大,甚至内容上的差异将被缩小,进一步增大了模型学习的困难。
-
从选择器架构上来看,选项对比网络在处理相似选项的效果并不理想。选择对比网络是针对RACE数据集提出,并在RACE数据集上取得了显著成果[24]。RACE数据集是从中学生英语考试中收集的大规模阅读理解数据集,备选答案之间存在明确的语义区别和内容差异,有经验的人类读者可以进根据选项之间的逻辑关系进行推理,进而缩小选择范围。深入研究选择器的预测后,我们发现选项对比网络倾向于选择长度较短的选项,这或许是原作者根据RACE数据集特征设计出的策略,然而这一模型特征在解决本实验中的选择问题的时候将带来负面影响,因为在本任务中选项长度和其正确概率不存在明显的依存关系。
第五章 总结与展望
在本章节中,我们将总结本实验中的工作与结果,并对下阶段工作提出可行的建议与展望。
5.1 总结
在本课题中,我们提出了一种基于深度预训练CLM的多模块化的MRC系统。在SQuAD2.0任务上,六种深度预训练CLM的实验结果表明我们提出的MRC系统设计合理,并且系统性能显著超过同型号的2020年的冠军系统Retro-Reader。
我们从观察MRC系统的预测和标准答案中发现问题:现有的MRC模型给出的答案在形式上并不完全正确,因此 MRC系统的性能很可能并没有被充分发挥出来。在进行初步的实验之后,我们发现:高分答案不一定总是阅读器给出的最高概率答案,但是往往在概率前四高的答案中。因此,我们找到合理的选题动机:设计一个具备答案选择器的MRC系统,使选择器能够针对特定任务的回答风格,选出阅读器给出的概率最高的四个备选答案中最符合标准答案风格的答案。
受到前人工作的启发,我们设计了一个具备选择器的多模块化的MRC系统:阅读器模块负责阅读理解和语义推理,针对每个问题给出四个备选答案及其概率;选择器模块负责针对数据集回答风格,给出每个备选答案是标准答案的概率;验证器模块负责将阅读器和选择器的预测结果进行加权结合,返回系统认为的最佳答案。
在六种深度预训练CLM上,我们的MRC系统性能优异,不仅相比基线模型有非常显著的性能提升,也超过了同型号的2020年SQuAD2.0排行榜冠军模型Retro-Reader。这样的实验结果既验证了我们的选题动机的合理性,也证明了我们的MRC系统设计的有效性。
5.2 工作展望
我们提出的具备选择器的MRC系统在SQuAD2.0数据集上获得了优异表现,更进一步,我们认为还有一些有效的工作在未来值得被尝试:
-
证明系统的泛化能力。我们目前仅在SQuAD2.0数据集上训练并评估了我们提出的MRC系统,为了研究系统的广泛有效性,我们认为很有必要在其他抽取式MRC任务上进行训练和评估,例如SQuAD1.0、NewsQA、TriviaQA等。
-
改进选择器的训练数据。正如我们在4.2.2部分的分析,将微调好的阅读器在训练集进行评估,得到的
train-nbest预测和标准答案在语义上过于接近,这加大了选择器学习的难度。我们认为值得借鉴Reddy等人的工作,将训练集分为五个部分,每次在四个部分上训练选择器,在剩下的一个部分上做预测,如此重复五次得到整个训练集的预测。 -
修改选择器的输入形式。我们目前的输入是将文章、问题和答案进行拼接,然后进行上下文词嵌入。由于文章和问题较长,答案部分的微小差异难以被较好呈现给模型,因此我们认为可以尝试只对问题和答案进行拼接,将问题的令牌标签设为0,答案的令牌标签设为1。这样的提议主要基于两个方面:一方面答案所占输入序列比例的提升能够帮助模型关注答案部分的语义和内容上的细微差异;另一方面,选择器不需要对文章进行理解,理论上删去输入中的文章并不会对模型产生负面影响,反而可能会由于减少了无效信息的干扰获得更好的效果。经过对数据集的统计与分析,我们发现问题和答案长度一般不多与64个令牌,因此我们建议可以分别降问题和答案补全到64个令牌,加上[SEP]和[CLS]令牌,获得长度为131的输入序列,从而极大减少模型对显存的要求。
-
重新设计选择器的编码器。目前我们使用阅读器微调后的深度预训练CLM作为选择器的编码器,然而,在研究模型输出之后,我们认为选择器需要更多从答案的形式和风格上进行学习,以做出符合数据集回答风格的预测。目前的阅读器在文章阅读和语意推理方面已经足够优秀,这表明深度预训练CLM在文章理解方面有较好的表现。但是,我们认为选择器对问题和答案进行理解并不是必要的,我们希望选择器能够更多地从形式上学习标准答案的风格,选出符合数据集回答风格的选项。因此,我们认为要想从根本上极大提升选择器的性能,应该选择对句法结构和语言搭配更加敏感的CLM作为编码器,遗憾的是,目前有关CLM的工作都聚焦于提升语言理解和语义推理能力。我们预测,一个对语言搭配和句法结构敏感的CLM作为编码器将极大提升选择器的准确度,进而极大提升我们提出的MRC系统的性能,使阅读器的性能得到充分的发挥,甚至叠加后得到更好的效果。
5.3 收获与感悟
在本项目中,项目选题、项目动机、系统设计和对比实验均为本人独立完成。在此过程中,虽有时迷茫,有时绝望,有时倍感艰难,但是独立经历一次完整科研项目流程令本人成长良多、收获颇丰。
通过本项目,本人对MRC领域常见的任务有了更加全面的了解,对MRC系统的设计和优化有了更加深刻的理解,对深度预训练CLM的使用已经较为熟练,已经初步具备了独立设计MRC系统并进行系统优化的能力。本人认为,最重要的成长和收获是能够独立发现并提出对领域有价值的研究问题,并能够想出切实可行的实验方案来尝试解决。在本项目的完成过程中,本人的成长和收获为研究生阶段的科研打下了一定的认知基础和能力基础。
致谢
随着毕业论文的结束,我本科阶段的学习和生活也接近尾声。四年前,我带着“立人”和“求知”的梦想来到上海交通大学,成为一名光荣的交大人。从开始时的懵懂,到中途的迷茫,再到现在的目光坚定,交大带给我的不仅是知识的增长和阅历的丰富,更是一名交大人所应该具备的人文素养和家国情怀。四年来,我时刻铭记在心唐文治老校长的教诲:“须知吾人欲成学问,当为第一等学问;欲成事业,当为第一等事业;欲成人才,当为第一等人才。而欲成第一等学问、事业、人才,必先砥砺第一等品行。”四年来,我勤奋刻苦、严谨求实、认真负责、积极进取,时刻要求自己成为一名合格的交大人。
在我成长的道路上,有在路边为我鼓掌的亲人,有为我指引方向的明灯,有令我斗志昂扬的前辈,有和我相伴而行的友人,有与我共同成长的伙伴。在此毕业论文完成之际,我希望由衷且正式地向他们致谢。
首先,感谢我亲爱的祖国!祖国的繁荣昌盛与和平稳定为我的学习和生活的方方面面提供了最有力的支持和保障。我不是生活在一个和平的时代,我只是生活在一个和平的国家。无论未来我身在何处,我始终相信祖国是我最坚实的后盾,我将始终怀有一颗爱国之心,时刻准备为祖国的发展和建设贡献自己的力量!清澈的爱,只为中国。
其次,衷心感谢我的父母!二十二年来,他们竭尽自己所能,让我在一个充满爱的环境中长大成人,让我树立了健康的人生观与价值观。在我追梦的道路上,他们非常尊重我的想法,始终支持我做出的决定,默默地做为我鼓掌的人。人生路上,我的父母从不要求我飞得有多高,总是关心我飞得累不累。少不更事时,总是羡慕别人家的父母;长大成人后,才真正明白父母清澈而稳重的爱,成为他们的孩子是我此生最大的幸运。
感谢我的导师赵海教授!导师渊博的专业知识,严谨的治学态度,精益求精的工作作风,诲人不倦的高尚师德,朴实无华、平易近人的人格魅力对我产生了深远的影响。为了培养我自主科研的能力,从论文的选题到完成,导师为我提供宏观上的指导与监督,每一步均由我独立提出并完成。在此过程中,我虽有时迷茫,有时绝望,有时倍感艰难,但是独立经历一次完整科研项目流程真的令我成长良多、收获颇丰。我十分认同和感激导师对我的期待与要求,相信经过本项目的锻炼,我为研究生阶段的科研打下了一定的认知基础和能力基础。研究生阶段我将继续师从赵海教授,希望自己能够做出更多科研成果!
感谢同实验室的张倬胜师兄,他在我的实验过程中为我提供了很多指点与启发。
感谢我的朋友们,孤独的时候有他们的陪伴,快乐的时光有他们能分享,生活的困难有他们的帮助。很幸运与他们相遇,希望未来的人生我们继续相伴前行。
感谢我的大学同学们,在学习中和我交流与讨论,在生活上和我相互帮助。他们的卓越时时刻刻提醒我意识到自己的不足,并奋发图强。
最后,感谢自己的努力与上进、积极与乐观、坚强与自信。四年来,我始终自我驱动,依靠自己积极的人生态度和出色的处事能力,完成了人生路上的一个又一个小目标。希望未来的自己更加坚定,不必妄自菲薄,不必等待炬火,选择自己无悔的人生。
参考文献
[1] ZHANG Z, ZHAO H, WANG R, et al. Machine Reading Comprehension: The Role of Contextualized Language Models and Beyond [EB/OL]. arXiv.org, 2020-05-13. (2020-05-13) [2021-05-16]. https://arxiv.org/abs/2005.06249.
[2] WANG C. A Study of the Tasks and Models in Machine Reading Comprehension [EB/OL]. arXiv.org, 2020-01-23. (2020-01-23) [2021-05-16].
https://arxiv.org/abs/2001.08635.
[3] ZHANG Z, YANG J, ZHAO H, et al. Retrospective Reader for Machine Reading Comprehension [EB/OL]. arXiv.org, 2020-12-11. (2020-12-11) [2021-05-16].
https://arxiv.org/abs/2001.09694.
[4] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving Language Understanding by Generative Pre-Training [EB/OL]. cs.ubc.ca, 2018, [2021-05-16]. https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
[5] DEVLIN J, CHANG M-W, LEE K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [EB/OL]. arXiv.org, 2019-05-24. (2019-05-24) [2021-05-16]. https://arxiv.org/abs/1810.04805.
[6] LAN Z, CHEN M, GOODMAN S, et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations [EB/OL]. arXiv.org, 2020-02-09. (2020-02-09) [2021-05-16]. https://arxiv.org/abs/1909.11942.
[7] LIU Y, OTT M, GOYAL N, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach [EB/OL]. arXiv.org, 2019-07-26. (2019-07-26) [2021-05-16]. https://arxiv.org/abs/1907.11692.
[8] CLARK K, LUONG M-T, LE Q V, et al. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators [EB/OL]. arXiv.org, 2020-03-23. (2020-03-23) [2021-05-16]. https://arxiv.org/abs/2003.10555.
[9] DAI Z, YANG Z, YANG Y, et al. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context [EB/OL]. arXiv.org, 2019-06-02. (2019-06-02) [2021-05-16]. https://arxiv.org/abs/1901.02860.
[10] HE P, LIU X, GAO J, et al. DeBERTa: Decoding-enhanced BERT with Disentangled Attention [EB/OL]. arXiv.org, 2021-03-18. (2021-03-18) [2021-05-16]. https://arxiv.org/abs/2006.03654.
[11] RAJPURKAR P, JIA R, LIANG P, et al. Know What You Don’t Know: Unanswerable Questions for SQuAD [EB/OL]. arXiv.org, 2018-06-11. (2018-06-11) [2021-05-16]. https://arxiv.org/abs/1806.03822.
[12] RAJPURKAR P, ZHANG J, LOPYREV K, et al. SQuAD: 100,000+ Questions for Machine Comprehension of Text [EB/OL]. arXiv.org, 2016-10-11. (2016-10-11) [2021-05-16]. https://arxiv.org/abs/1606.05250.
[13] LAI G, XIE Q, LIU H, et al. RACE: Large-scale ReAding Comprehension Dataset From Examinations [EB/OL]. arXiv.org, 2017-12-05. (2017-12-05) [2021-05-16]. https://arxiv.org/abs/1704.04683.
[14] REDDY S, CHEN D, MANNING C D, et al. CoQA: A Conversational Question Answering Challenge [EB/OL]. Transactions of the Association for Computational Linguistics, MIT Press, 2019-08-01. (2019-08-01) [2021-05-16].
[15] SUN K, YU D, CHEN J, et al. DREAM: A Challenge Dataset and Models for Dialogue-Based Reading Comprehension [EB/OL]. arXiv.org, 2019-02-01. (2019-02-01) [2021-05-16]. https://arxiv.org/abs/1902.00164.
[16] HERMANN K M, KOČISKÝ T, GREFENSTETTE E, et al. Teaching Machines to Read and Comprehend [EB/OL]. arXiv.org, 2015-11-19. (2015-11-19) [2021-05-16]. https://arxiv.org/abs/1506.03340.
[17] HOCHREITER S, SCHMIDHUBER J. Long Short-Term Memory [EB/OL]. Neural Computation, MIT Press, 1997-11-15. (1997-11-15) [2021-05-16]. https://direct.mit.edu/neco/article/9/8/1735/6109/Long-Short-Term-Memory.
[18] CHUNG J, GULCEHRE C, CHO K H, et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling [EB/OL]. arXiv.org, 2014-12-11. (2014-12-11) [2021-05-16]. https://arxiv.org/abs/1412.3555.
[19] VASWANI A, SHAZEER N, PARMAR N, et al. Attention Is All You Need [EB/OL]. arXiv.org, 2017-12-06. (2017-12-06) [2021-05-16].
https://arxiv.org/abs/1706.03762.
[20] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word. representations [EB/OL]. arXiv.org, 2018-03-22. (2018-03-22) [2021-05-16].
https://arxiv.org/abs/1802.05365.
[21] YANG Z, DAI Z, YANG Y, et al. XLNet: Generalized Autoregressive Pretraining for Language Understanding [EB/OL]. arXiv.org, 2020-01-02. (2020-01-02) [2021-05-16]. https://arxiv.org/abs/1906.08237.
[22] REDDY R G, SULTAN M A, KAYI E S, et al. Answer Span Correction in Machine Reading Comprehension [EB/OL]. arXiv.org, 2020-11-06. (2020-11-06) [2021-05-16]. https://arxiv.org/abs/2011.03435.
[23] ZHAO Z, WU S, YANG M, et al. Robust Machine Reading Comprehension by Learning Soft labels [EB/OL]. ACL Anthology, [2021-05-16].
https://www.aclweb.org/anthology/2020.coling-main.248/
[24] RAN Q, LI P, HU W, et al. Option Comparison Network for Multiple-choice Reading Comprehension [EB/OL]. arXiv.org, 2019-03-07. (2019-03-07) [2021-05-16]. https://arxiv.org/abs/1903.03033.
[25] WOLF T, DEBUT L, SANH V, et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing [EB/OL]. arXiv.org, 2020-07-14. (2020-07-14) [2021-05-16]. https://arxiv.org/abs/1910.03771.
[26] PASZKE A, GROSS S, MASSA F, et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library [EB/OL]. arXiv.org, 2019-12-03. (2019-12-03) [2021-05-16]. https://arxiv.org/abs/1912.01703.
[27] DUA D, WANG Y, DASIGI P, et al. DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs [EB/OL]. arXiv.org, 2019-04-16. (2019-04-16) [2021-05-16]. https://arxiv.org/abs/1903.00161.