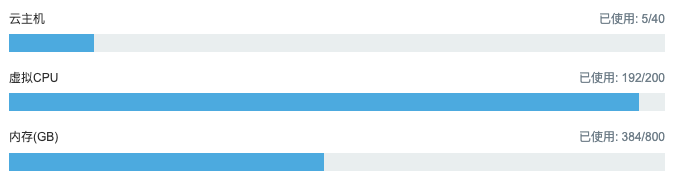基于云计算平台的联邦学习部署和研究
- 作者:王金元
- 学号:121260910054
- 日期:2022.01.14
1. 项目介绍
在本项目中,我们将参考这篇论文,根据其中的Algorithm 1 来实现FedAvg算法。我们使用Conda环境中的Python + PyTorch进行编程,并在上海交通大学云计算平台部署模型进行训练。 我们选择基于PyTorch实现的MNIST手写数字辨识任务,使用FedAvg算法来实现在多个客户端的联邦学习。
在本项目中,我们手动实现非独立同分布(Non-IID)的MNIST数据集,并探索不同数量的客户机对算法准确率的影响。我们的模型部署在上海交通大学云计算平台上,所有的模型训练和参数更新都是基于CPU的。在初步的实验中,我们使用循环算法来实现多客户机的训练,在后续的实验中,我们使用Python的多进程模块来进一步实现客户机的并行计算。
本实验的计算资源为:上海交通大学云计算平台
A服务器 * 1:
OS: Ubuntu 20.04 LTSMemory: 128GBProcessor: Intel Xeon Processor @ 2.4GHz * 64Disk Capacity: 500GBGPU: None
B服务器 * 4:
OS: Ubuntu 20.04 LTSMemory: 64GBProcessor: Intel Xeon Processor @ 2.4GHz * 32Disk Capacity: 500GBGPU: None
实验环境:
Anaconda3-2021.11-Linux-x86_64Python 3.8.12PyTorch 1.10.1
2. 循环式联邦学习系统
在本实验中,我们将通过循环来模拟FedAvg算法。服务器端和客户端分别写在server.py 和client.py 文件中。
本实验部署在上海交通大学云计算平台A服务器。

根据这个算法,我们可以写出如下的伪代码:
2.1 搭建服务器
在server.py 中,我们设置了客户机群的大小nc、每轮通讯的活跃客户机比例cf、总的通讯轮数ncomm 以及训练数据是否IIDiid.
一些关键参数如下:
- 具体代码细节请参考
server.py
2.2 搭建客户机
在client.py 中,我们定义了单个客户端对象SingleClient和客户机群对象ClientGroup,客户机群储存所有客户机对象,每轮通讯收到激活的客户机名称,激活相应客户机并分配相应的训练数据集。
- 具体代码细节请参考
client.py
2.3 非独立同分布(Non IID)数据集
在data_utils.py中,我们定义了一个获取数据的对象get_dataset ,我们可以通过参数isIID来控制产生的数据集是否独立同分布(IID)。在本实验中,我们使用MNIST数据集有60000个训练样本。以100个客户机为例,IID数据集是将数据集打乱,每个客户机分配600个训练样本,Non IID是先根据标签对数据集进行排序,然后将其划分为200组大小为300的数据切片,然后分给每个客户机2组切片作为训练样本。
- 具体代码细节请参考
data_utils.py
2.4 深度学习模型
在models.py中,我们创建了两个模型mnist_cnn和mnist_2nn,前者是一个有两个卷积层的卷积神经网络(CNN),后者是一个两层的全联接神经网络(FCN),我们将在后续的实验中对比两个模型在联邦学习背景下的学习效果。
2.5 部署循环式联邦学习
- 我们在上海交通大学云计算平台A服务器部署模型,运行
server.py
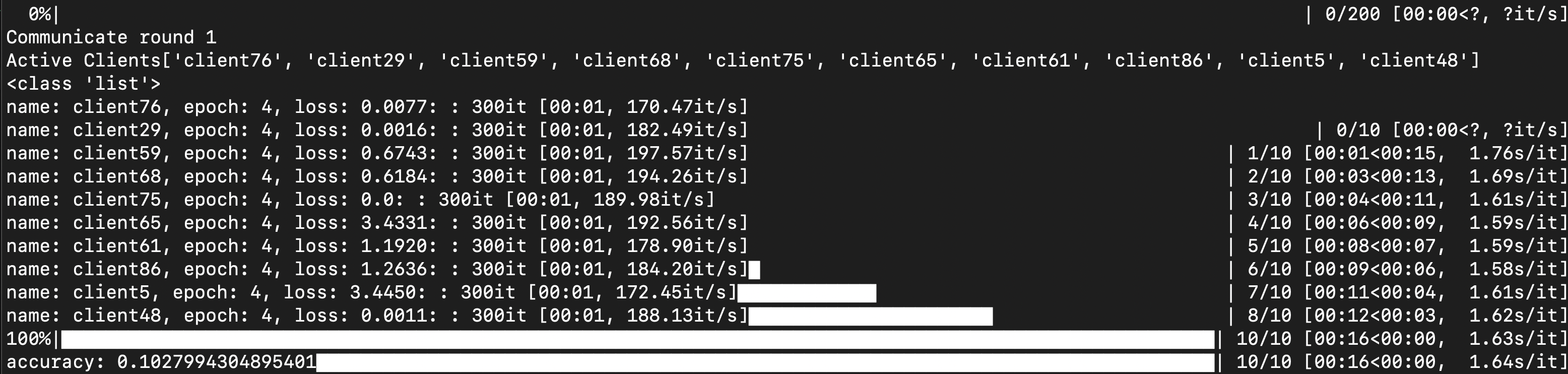
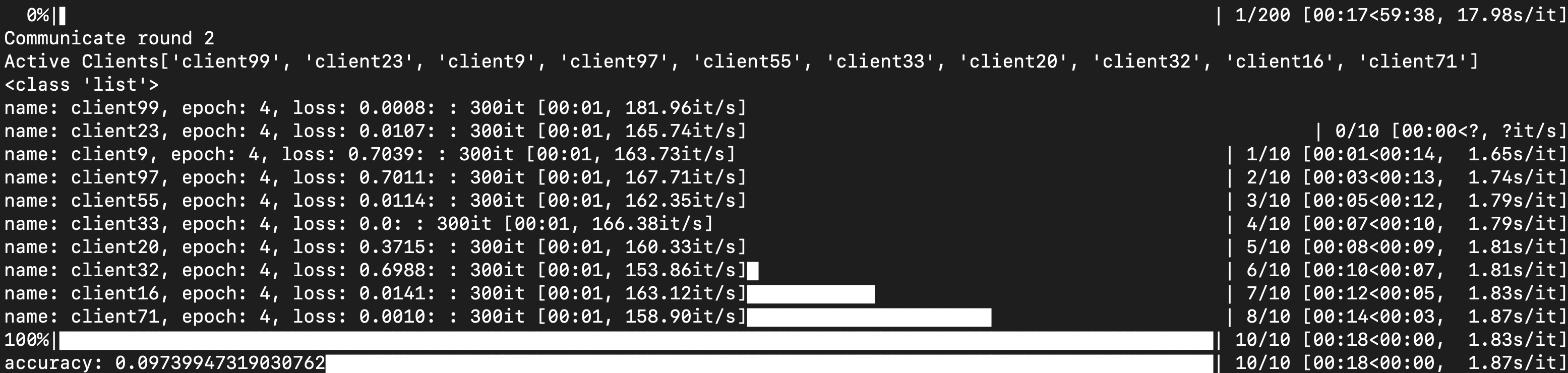
- 下图所示的实验中,客户机总数为100,更新比例
cf=0.1,可以观察到前两轮通讯结果:每次活跃的10个客户机各不相同。
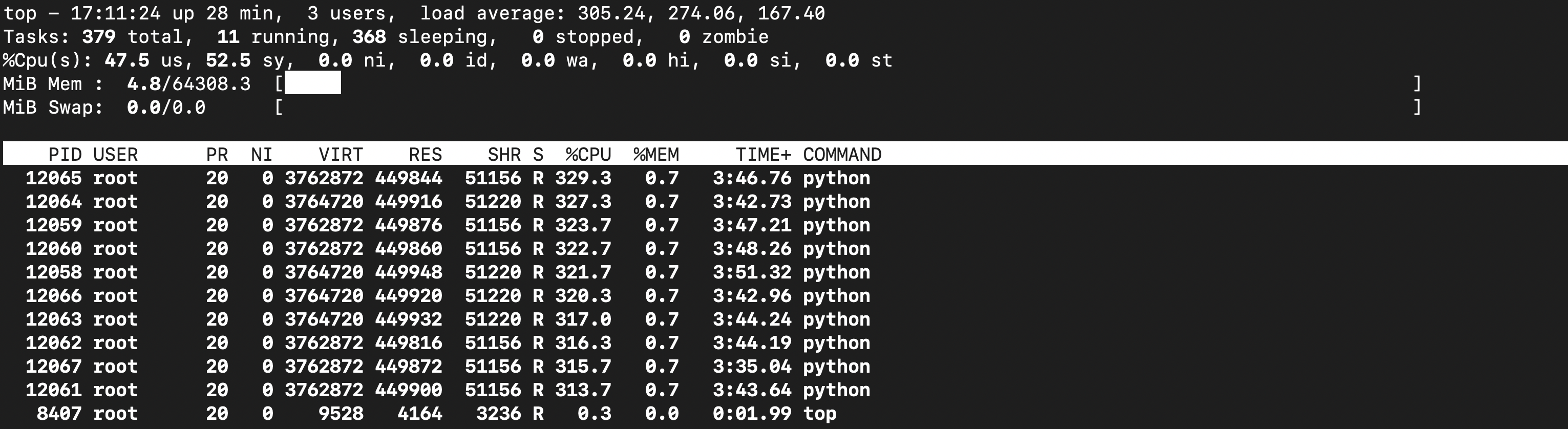
- 我们观察一下云计算服务器的资源占用情况,我们确认只有一个进程在循环运算

3. 并行式联邦学习系统
在本实验中,我们将通过Python多进程模块来并行化实现FedAvg 算法。服务器和客户机的代码分别在server_para.py和client_para.py中。
本实验部署在上海交通大学云计算平台四台B服务器。
3.1 服务器端并行式实现
在客户机中,我们取消了每个客户机展示当前训练状态的设置,其他部分和循环式客户机保持一致。在服务器端,我们使用Python多进程模块中的进程池来利用多进程来实现多客户机的并行式联邦学习训练,相应的伪代码如下:
3.2 部署并行式联邦学习
- 我们在上海交通大学云计算平台B服务器部署并行式联邦学习,使用32个CPU、100个客户机、50轮通讯
- 并行式联邦学习训练时的效果如下,在下图的实验中,我们选择100台客户机,更新比例
cf=0.1,也就是同时有10台客户机在并行计算,以下为前两轮通讯效果

- 此时我们观察到并行式联邦学习的速度(
83s/epoch)远远低于循环式联邦学习(17s/epoch)。需要说明的是,并行式联邦学习是在一台32核的交大云服务器上进行的,两次实验的配置仅CPU核数不同,但是时间相差四倍,可能是并行化计算框架还需要进行优化。 - 我们再观察一下云计算服务器的资源占用情况,我们确认有10个进程在并行运算。
4. 实验设置和结果
在本章节的实验中:
- 如果没有特殊说明,我们使用的都是CNN模型。
- 如果没有特殊说明,我们使用的训练数据都是Non-IID的。
- 如果没有特殊说明,我们使用的都是循环式联邦学习。
4.1 联邦学习参与率研究
在本实验中,我们固定客户机的数量为100,我们研究每轮通讯中激活的客户机的比例cf(论文中的参数)对联邦学习的影响。
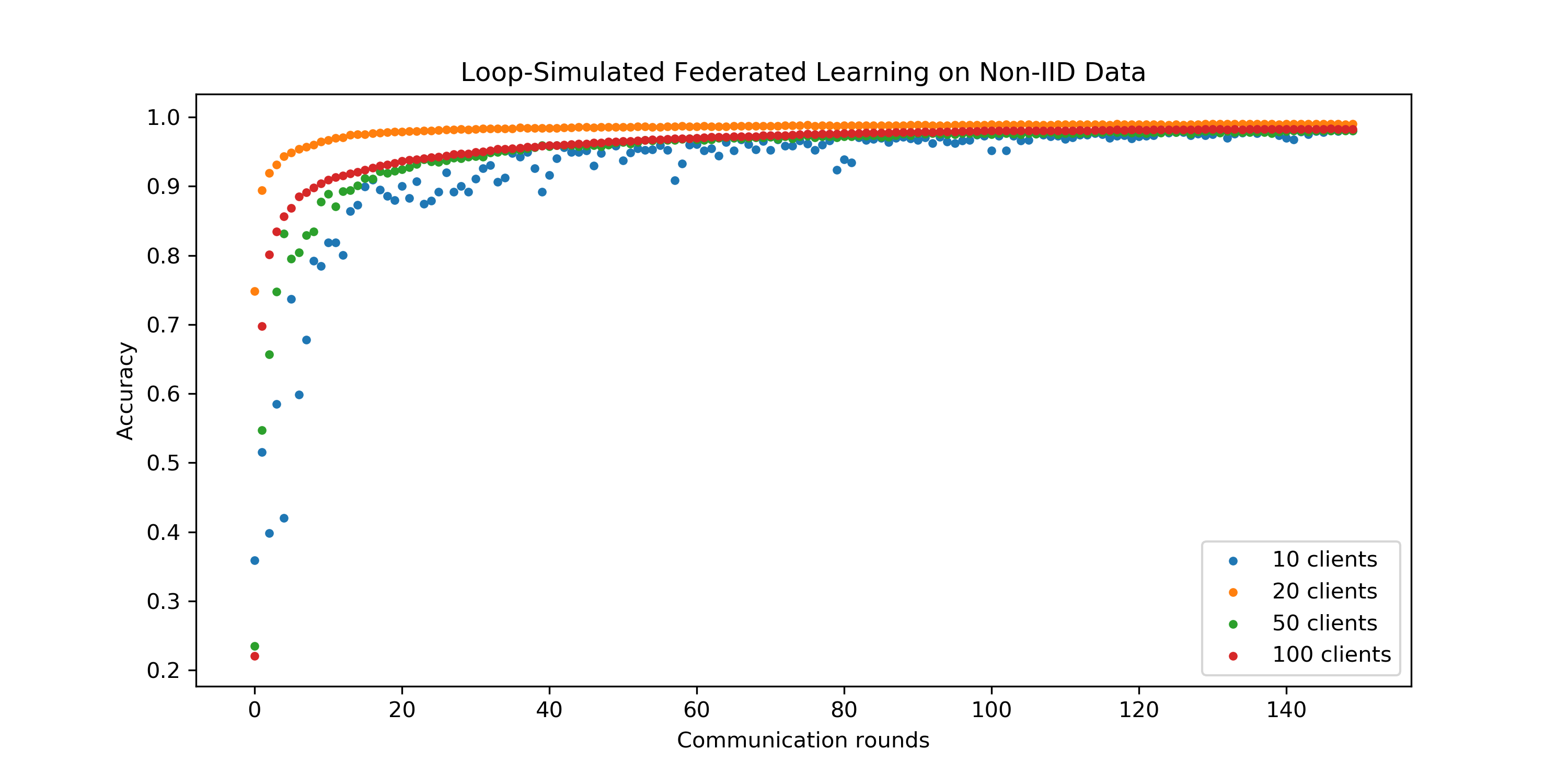
- 如上图,在我们的实验中,我们观察到对于Non-IID数据:
- 参与更新的客户机比例过高和过低都会导致模型收敛变慢,最佳比例系数是,这和论文中的结论不一致,论文中的最佳参数在我们实验中表现最差;
- 无论值大小,模型最终收敛到几乎相同的准确率,值只是影响模型收敛速度,并不影响模型收敛结果。
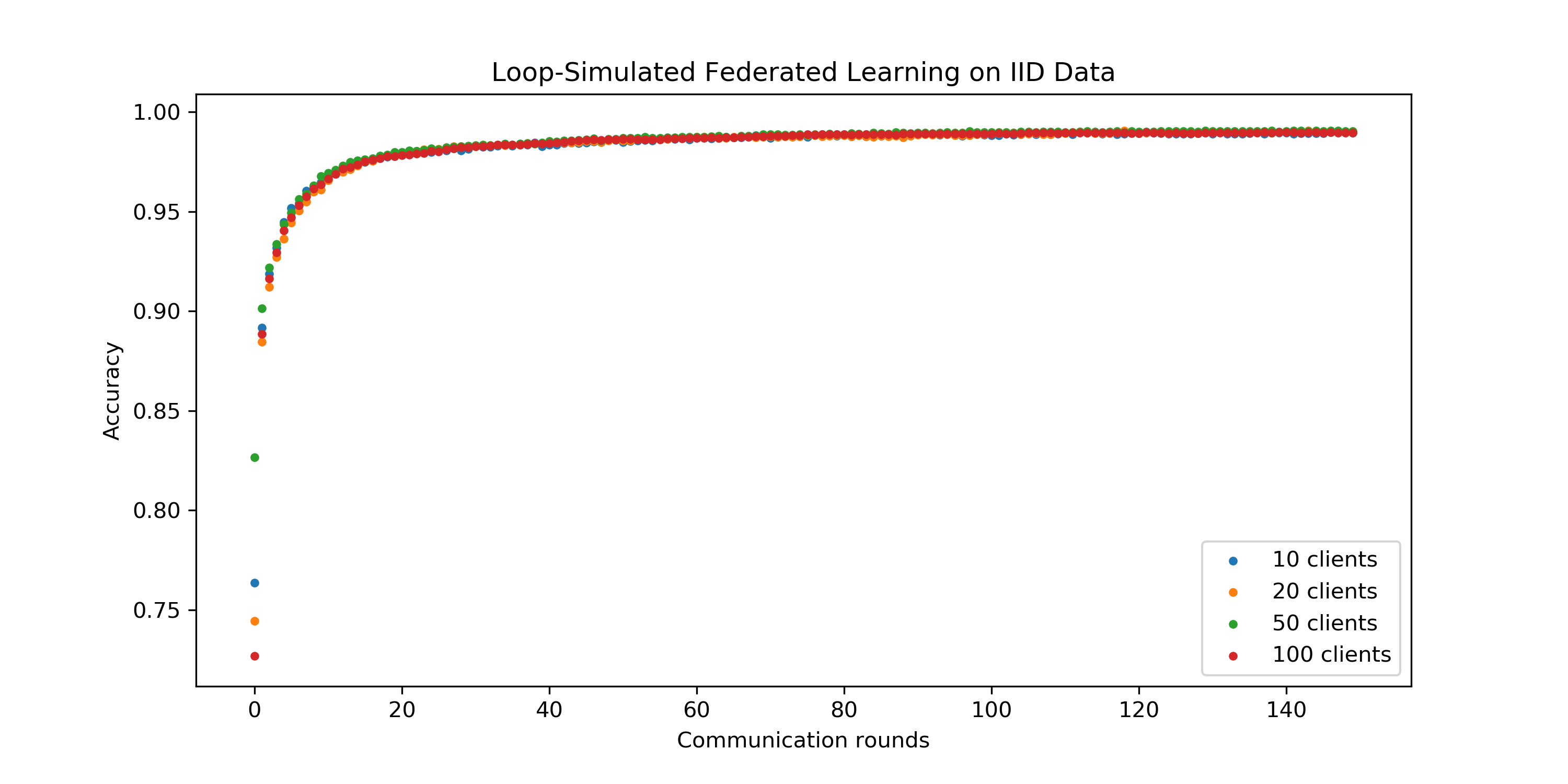
- 如上图,在我们的实验中,我们观察到对于IID数据:
- 参与更新的客户机比例并不影响模型收敛速度和收敛性;
- IID数据上模型收敛速度快于Non-IID数据。
4.2 联邦学习规模研究
在本实验中,我们控制客户机更新比例系数不变,我们改变每次参与联邦学习的客户机总数,来研究联邦学习规模对模型准确率的影响。在训练过程中,我们保持模型的学习率为lr=0.01.
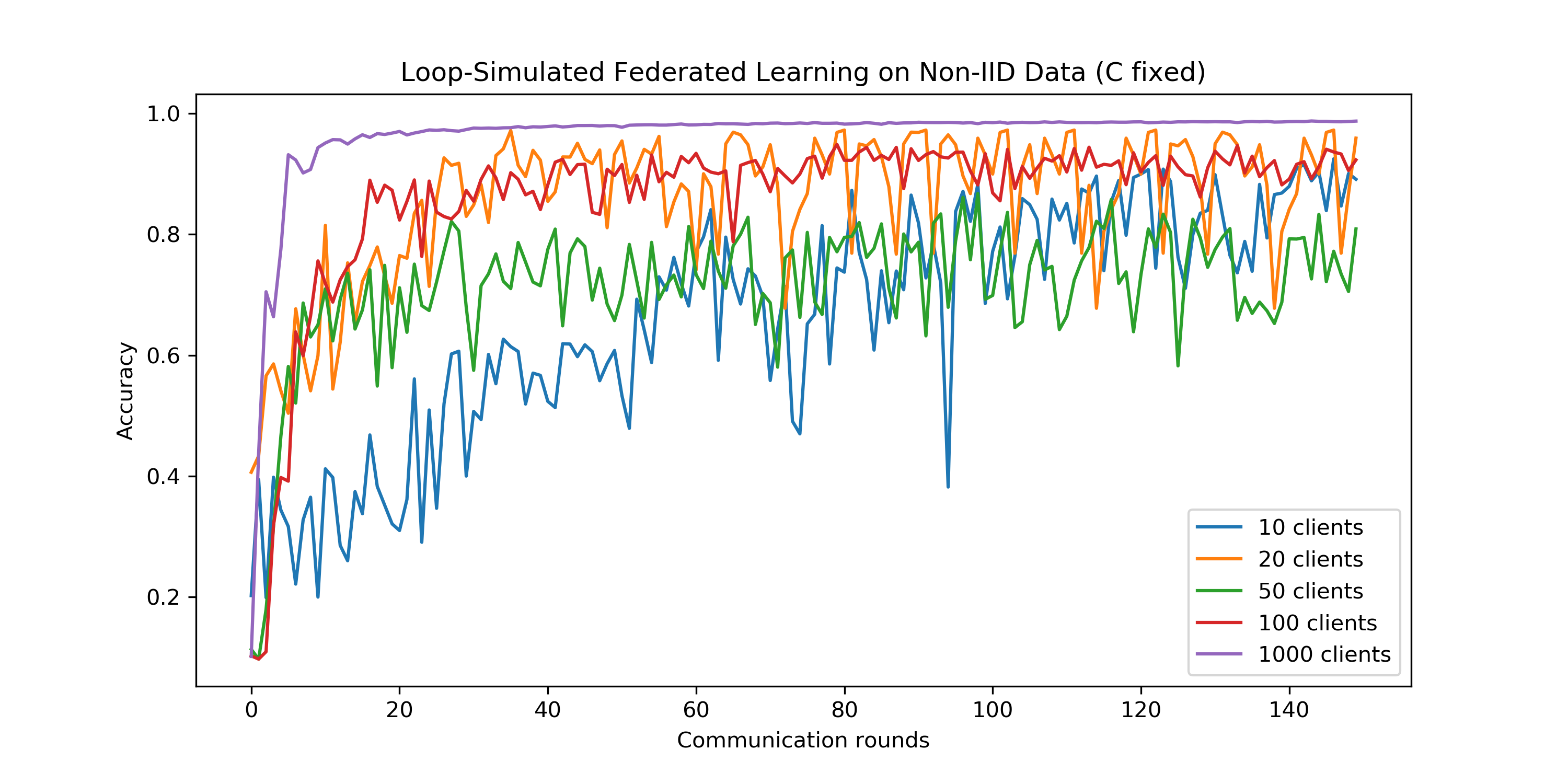
- 本实验中我们有如下思考:
- 我们发现,随着联邦学习规模的不断增大,模型收敛的速度更快,收敛也更加平滑和稳定。在真实的世界中,用户数远多于1000,当然模型也会更加复杂,因此优化联邦学习一般有两个方向:增加联邦学习规模、简化模型
- 尽管20个客户端的时候模型收敛的准确率接近于100个客户端的准确率,但是准确率波动较大,在一定程度上很难被认为收敛。
- 我们认为这可能是因为我们设置的学习率过大,当每次参与更新的客户机数量比较少的时候,应该适当调小学习率。
4.3 联邦学习中的学习率
本实验中,我们来设计一个简单的实验初步验证上一部分我们的猜想:当每次参与更新的客户机数量比较少的时候,应该适当调小学习率。
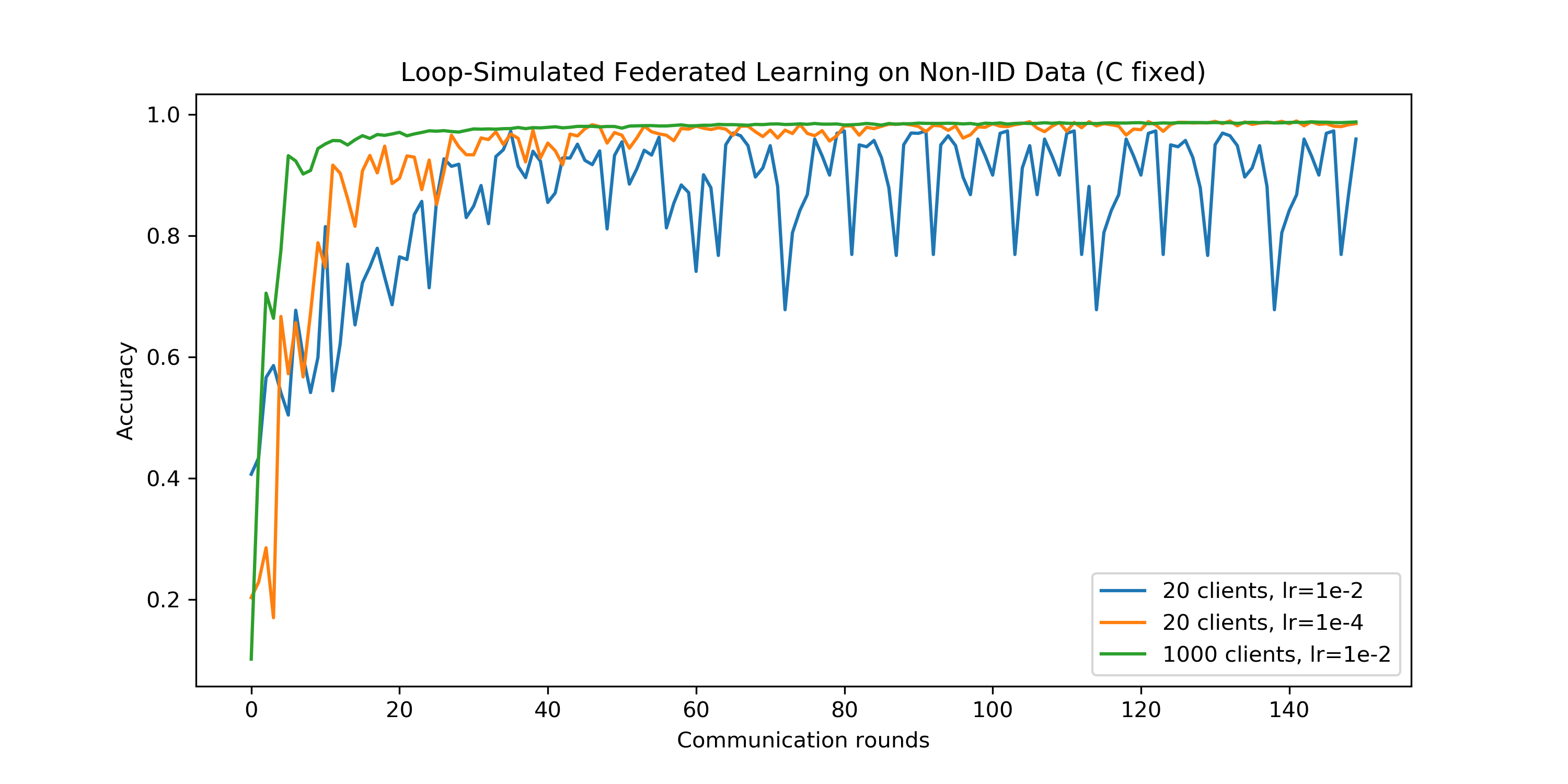
- 我们发现,调小学习率之后的20个客户端的模型收敛更加平稳,并且最终收敛于1000个客户端的准确率。
- 由于时间有限,上图结果只能初步验证我们的猜想,我们仍需进行多组实验才能进一步验证。
4.4 不同模型的联邦学习
在本实验中,我们对比了两种不同的神经网络模型的联邦学习过程。我们对比的模型分别是一个双层的全联接网络(FCN)和上面一直在用的双层卷积神经网络(CNN)。
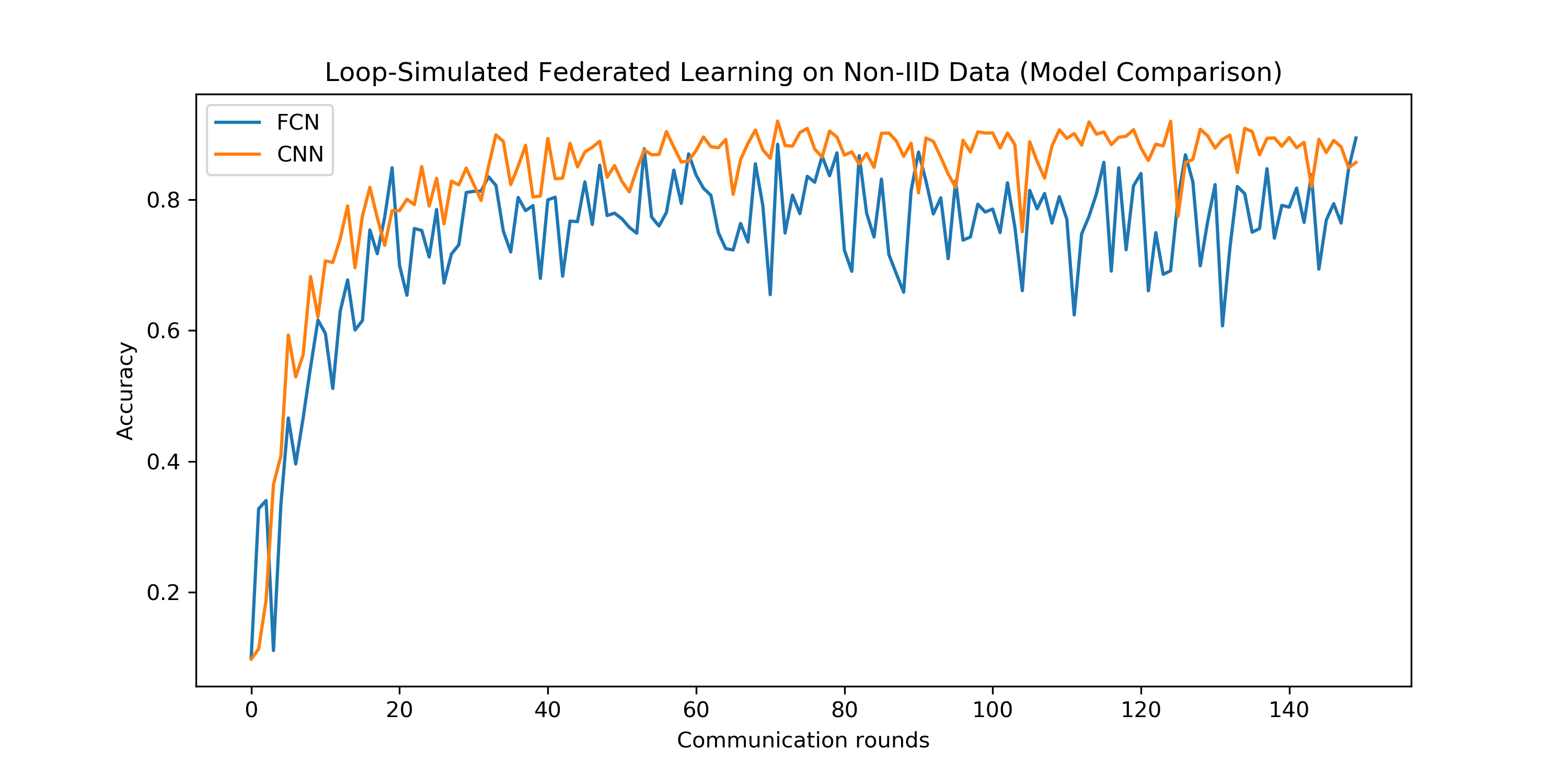
- 如上图所示,我们发现虽然FCN比CNN模型简单,但是两个模型收敛速度大致相同,FCN的准确率波动较大,CNN的准确率收敛相对来说比较稳定。
- FCN的准确率收敛值略低于CNN的准确率收敛值,我们认为这很合理,因为FCN模型更简单一些,准确率理应更低一些。
- 由此,我们猜想更简单的模型可能需要更小的学习率来保持稳定收敛。
5. 并行式联邦学习
我们分别部署了客户机总数为50、100、200的并行式联邦学习,然而很遗憾训练并没有成功。由于时间有限,我暂时没有更多的精力去寻找并行式联邦学习代码中存在的问题。在本章节,我们展示一些并行式联邦学习的失败的运行记录,以作为工作量证明。
5.1 工作量证明
- 100个客户机,更新比例10%,50轮通讯

- 50个客户机,更新比例10%,50轮通讯

- 200个客户机,更新比例10%,50轮通讯

5.2 期望结果
参考其他同学的工作,并行式联邦学习的期望效果图如下:
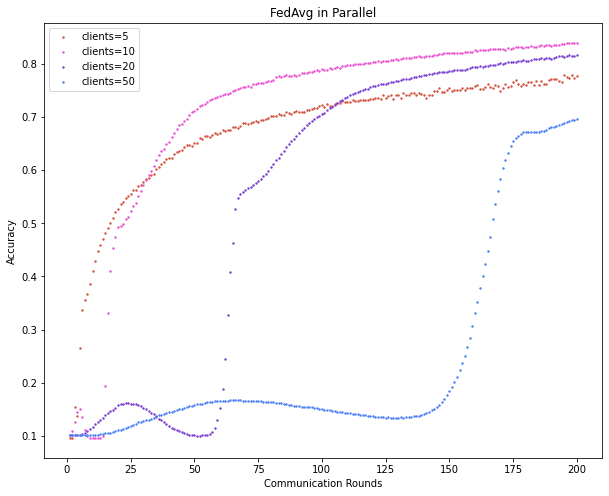
附录
上海交通大学云计算平台
- 本实验的计算资源