基于无服务计算框架的分布式训练及机器学习应用
作者:王金元
学号:121260910054
日期:2022.01.11
任务1: 基于无服务器计算框架的机器学习应用
首先,我们要选择合适的无服务器计算框架,在此项目中,我们有如下三个选择:
- AWS Lamda. AWS Lambda是最为广泛应用的无服务器计算框架,AWS为学生提供了免费的使用额度,使我们可以在AWS Lambda上部署我们的计算函数。
- OpenWhisk. OpenWhisk是一个开源的无服务器计算框架,我们需要在本地部署 OpenWhisk 框架,并提交框架部署方法记录。
- 其他开源无服务器计算框架。
在本项目中,我们选择使用开源的无服务器计算框架OpenWhisk。Openwhisk是属于Apache基金会的开源Faas计算平台,由IBM在2016年公布并贡献给开源社区。IBM Cloud本身也提供完全托管的OpenWhisk Faas服务IBM Cloud Function。从业务逻辑来看,OpenWhisk同AWS Lambda一样,为用户提供基于事件驱动的无状态的计算模型,并直接支持多种编程语言。
OpenWhisk特点:
- 高性能,高扩展性的分布式FaaS计算平台
- 函数的代码及运行时全部在Docker容器中运行,利用Docker engine实现FaaS函数运行的管理、负载均衡、扩展.
- OpenWhisk所有其他组件(如:API网关,控制器,触发器等)也全部运行在 Docker容器中。这使得OpenWhisk全栈可以很容易的部署在任意IaaS/PaaS平台上。
- 相比其他FaaS实现(比如OpenFaaS),OpenWhisk更像是一套完整的Serverless 解决方案,除了容器的调用和函数的管理,OpenWhisk 还包括了用户身份验证/鉴权、函数异步触发等功能。
目前支持的语言: Nodejs, Python, Java, php, Ruby, Go, Rust, dotnet, Ballerina, blackBoxes。
本实验的计算资源为:
-
计算平台:
OS: macOS Catalina 10.15.7Memory: 32GBProcessor: Intel Core i9-9880H @ 2.3GHz * 16Platform: VMware Fusion Pro 11.5.0
-
虚拟机环境:
OS: Ubuntu 20.04LTSMemory: 16GBDisk Capacity: 110GBProcessor: Intel Core i9-9880H @ 2.3GHz * 8
本实验的工作目录是: cc/lab2/Task1-Serverless/
1. 安装OpenWhisk无服务器计算框架
1.1 安装依赖
- 运行脚本
setup-deps.sh
setup-deps.sh
1.2 安装docker
- 运行脚本
setup-docker.sh
setup-docker.sh
1.3 安装OpenWhisk
- 运行脚本
setup-openwsk.sh
setup-openwsk.sh
1.4 启动OpenWhisk
- 输入命令,启动OpenWhisk服务器
- 看到下图
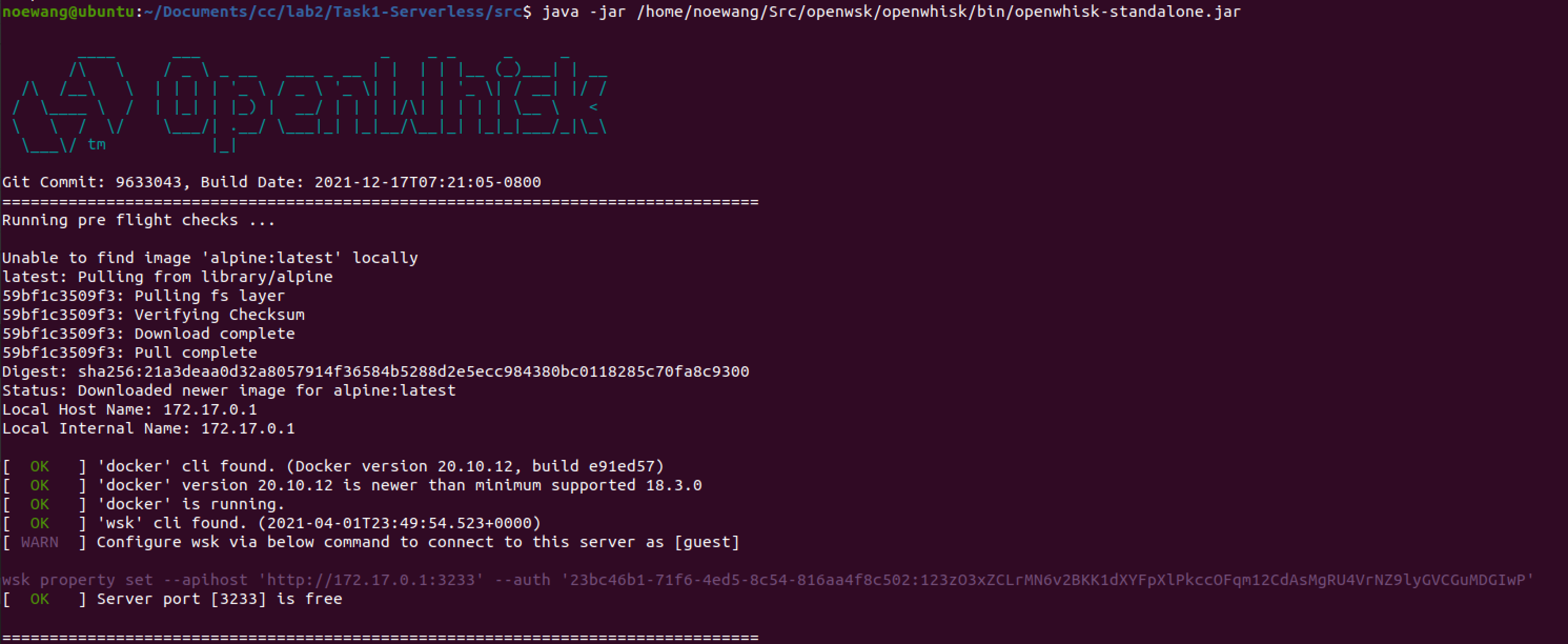
- 当前的OpenWhisk的例子的凭证:
- 在新的终端,连接到服务器
- 现在我们可以通过
wsk命令来操作OpenWhisk了
1.5 验证OpenWhisk安装
- 创建一个
test.js来测试一下OpenWhisk
- 创建OpenWhisk行为(Action)来连接这个函数
- 运行这个函数
2. 部署机器学习应用
本章节使用的ML预测性任务为基于CNN的MNIST手写数字辨识项目,我们从GitHub 上找到了一个使用PyTorch在MNIST数据集上训练好的CNN模型,以及相关的部署代码。由于OpenWhisk框架的限制,所有函数的输入和输出都必须为.json 文件,这使得直接传入图片变得有些困难。该代码将ML模型包装成一个WebApp,以便于OpenWhisk的函数在docker容器中可以仅通过URL来获取图片。
在本实验中,我们在一个开源的Docker容器中,下载已经训练好的开源的模型检查点,使用HTTP Server将其加载到模型,并使用OpenWhisk框架进行预测任务。我们的工作流程如下:
- 从开源项目中搭建Docker镜像;
- 在Docker中运行基于flask的WebApp;
- 创建OpenWhisk Action;
- 启动HTTP Server;
- Invoke刚才定义的OpenWhisk Action,传入预测图片的URL;
- 获得预测结果。
2.1 定义机器学习任务
在本实验中,我们选择基于MNIST数据集的手写数字辨识项目,模型为基于PyTorch实现的LeNet5模型。
MNIST数据集由训练集和测试集组成,训练集包含60000个训练样本,测试集包含10000个测试样本。如下图,每个样本都是大小为28*28的单通道黑白图片,图片内容为手写数字,一共有10个类,标签分别为0-9. 该任务为预测型任务,要求模型对输入图片进行分类。

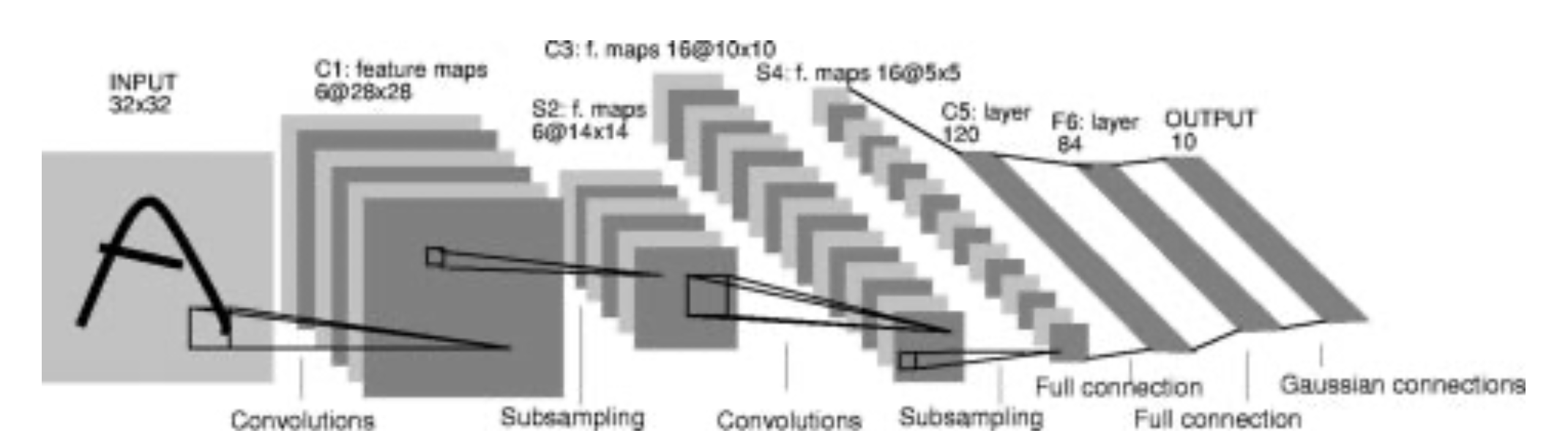
LeNet5是一个简单有效的卷积神经网(CNN),由YANN LECUN等人于1998年提出,它的结构如下图。本实验中,我们使用基于PyTorch实现的LeNet5模型进行预测。
2.2 为机器学习应用创建Docker镜像
OpenWhisk支持Docker行为,但是存在一些限制,为此,我们从公开的Docker镜像中找到了一个合适于本实验的natrium233/python3action-mnist:1.3,它满足:
- 此镜像基于Ubuntu;
- 它下载和安装了conda;
- 它创建了一个虚拟环境叫做
mnist; - 在
mnist环境中安装了flask和PyTorch; - 它能够自行部署此ML应用。
- 这个镜像的
dockerfile如下:
- 我们也可以运行
build.sh来在本地创建Docker镜像,但是需要OpenWhisk只能从公开的Docker镜像运行,因此还需要将其公布。 - 在后续的实验中,我们将使用其他用户已经公开的Docker镜像
natrium233/python3action-mnist:1.3来进行之后的实验。
2.3 基于HTTP Server部署机器学习应用
2.3.1 启动OpenWhisk无服务器计算框架
- 在
Terminal 1启动OpenWhisk
2.3.2 启动HTTP Server
- 在
Terminal 2进入测试图片所在的文件夹,启动HTTP Server,端口为8000。这一步是为了将本地的图片放在HTTP服务器上,使得OpenWhisk的函数可以通过网络URL来下载图片到容器中,并输入模型。
2.3.3 从Docker镜像创建OpenWhisk行为
- 在
Terminal 3创建一个OpenWhisk的Action,它使用公开的Docker镜像natrium233/python3action-mnist:1.3,叫做mnist。在这个Docker镜像中,一个flask服务器已经加载训练好的模型检查点并可以进行预测,详情见$WORK_DIR/code/deploy-flask.py
2.3.4 唤醒OpenWhisk行为
- 在
Terminal 3Invoke这个Action,我们传入的是label=0的手写数字图片,我们看到模型预测的结果也为0
2.3.5 模型预测结果
- 我们在
Terminal 3中换不同的label的图片多进行几次尝试:
- 在
Terminal 2中,我们可以看到HTTP访问记录:
任务2:基于无服务器计算框架的分布式训练
在本实验中,我们需要自定义分布式机器学习训练任务,在任务1中选择的无服务器计算框架部署训练任务,并进行分布式训练。在任务1中,我们选择开源的无服务器计算框架OpenWhisk,并选择基于PyTorch实现的MINIST数据集手写数字辨识任务。在本任务中,我们依然选择MNIST手写数字辨识任务,并基于OpenWhisk框架对任务1中的LeNet5模型进行分布式训练。
本实验的计算资源为:
-
计算平台:
OS: macOS Catalina 10.15.7Memory: 32GBProcessor: Intel Core i9-9880H @ 2.3GHz * 16Platform: VMware Fusion Pro 11.5.0
-
虚拟机环境:
OS: Ubuntu 20.04LTSMemory: 16GBDisk Capacity: 110GBProcessor: Intel Core i9-9880H @ 2.3GHz * 8
本实验的工作目录是: WORK_DIR=cc/lab2/Task2-DistributedTraining
1. 定义分布式机器学习任务
在本任务中,我们依旧选择MNIST手写数字辨识任务,选择基于PyTorch实现的LeNet5作为模型。MNIST数据集的训练集包含60000个样本,我们将其平均分为6份,储存在$WORK_DIR/code/dataset_deploy中。我们将在这六个数据集上进行分布式训练。
2. 创建Docker镜像
在本实验中,我们使用公开的Docker镜像natrium233/python3action-dist-train-mnist:1.1,它的Dockerfile如下:
- 我们也可以运行
scripts/build.sh来在本地创建Docker镜像,但是需要OpenWhisk只能从公开的Docker镜像运行,因此还需要将其公布。 - 在后续的实验中,我们将使用其他用户已经公开的Docker镜像
natrium233/python3action-dist-train-mnist:1.1来进行实验。
3. 部署分布式训练任务
3.1 启动OpenWhisk无服务器计算框架
- 在
Terminal 1启动OpenWhisk无服务器计算框架
3.2 启动HTTP服务器
- 在
Terminal 2进入目录code/dataset_deploy,启动HTTP服务器,端口为8000. 这一步是将本地的训练集放在HTTP服务器上,使得OpenWhisk的函数可以通过网络URL来下载训练集到容器中,并传递给模型。
3.3 启动分布式训练服务器
- 在
Terminal 3运行code/run_server.py脚本,启动分布式训练服务器,端口为29500.
3.4 从Docker镜像创建OpenWhisk行为
- 在
Terminal 4创建一个OpenWhisk的Action,它使用公开的Docker镜像natrium233/python3action-dist-train-mnist:1.1,叫做dist-train。在这个Docker镜像中,一个worker正在等待数据集进行训练,详情见$WORK_DIR/code/run_worker.py
3.5 唤醒分布式训练行为
- 在
Terminal 4中运行wsk-invoke-dist-train-2workers.sh
- 在
Terminal 4中输入docker stats查看资源占用情况
- 在
Terminal 2,我们可以看到数据集访问记录
- 在
Terminal 3,我们可以看到分布式训练服务器的记录(1个Optimization Step)
3.6 对比实验
- 我们继续运行
wsk-invoke-dist-train-4workers.sh,来观察增加分布式训练的进程对每个进程的影响
- 虽然我们尝试添加4个workers,然而我们只观察到3个workers在运行,我们猜测这应该是OpenWhisk对运行内存有限制,可能为512MB。
- 我们在HTTP服务器观察到4个workers分别提取了训练文件,如下
- 我们看到虚拟机的内存资源充足,性能瓶颈为CPU,这符合我们的预期
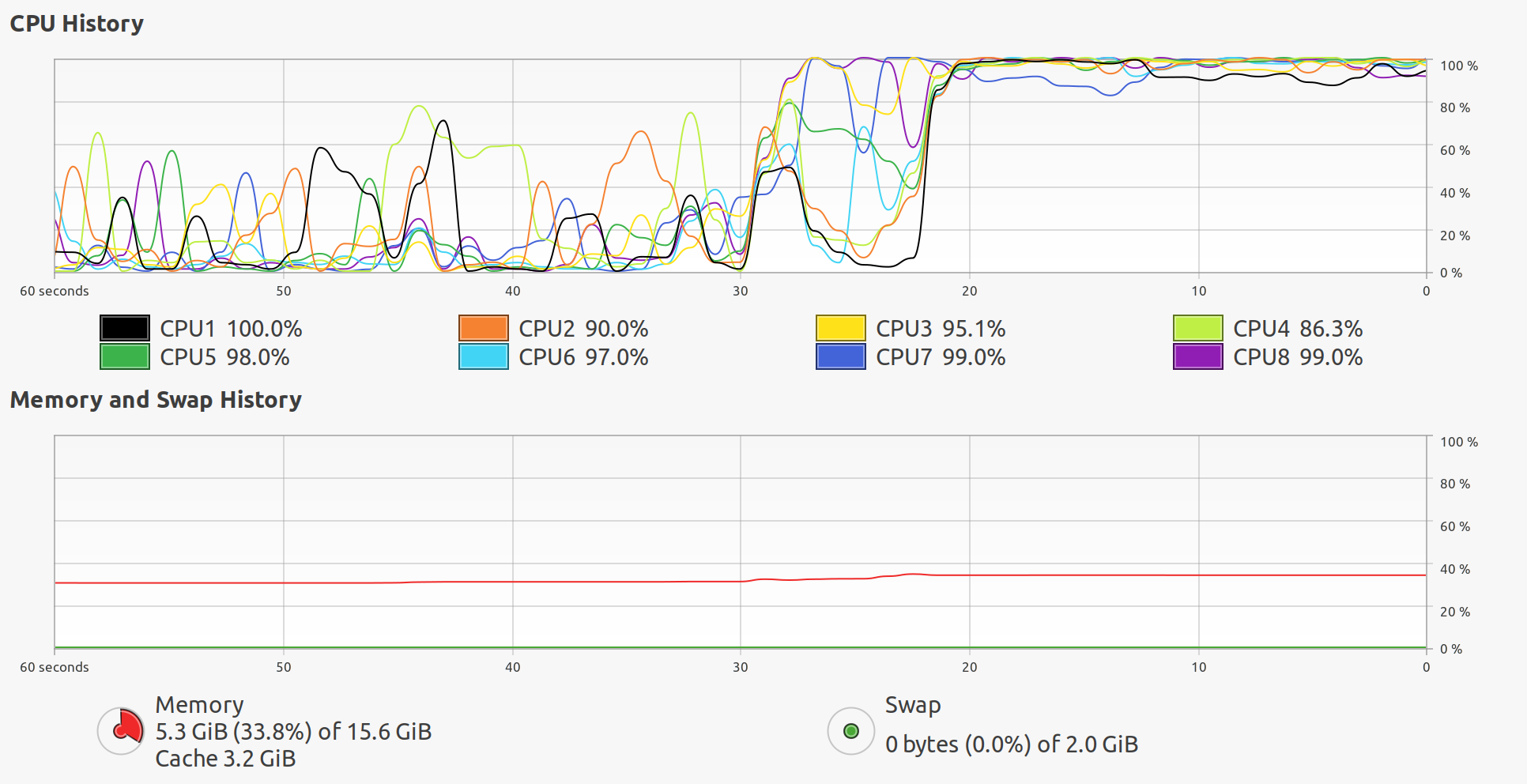
- 从我们的对比实验可以看出来,当有2个worker的时候,虚拟机分布式学习的CPU利用率大约为:;当有3个worker的时候,虚拟机分布式学习的CPU利用率大约为: ,略有下降。