计算机视觉和动态虚拟现实
作者:王金元
教师:李颢
日期:2022.01.15
1. 任务简介
近年来,计算机视觉 (CV) 在解决各个领域的大量具有挑战性的问题方面取得了长足的进步和显着的成功。 尽管近来CV学术界的繁荣主要得益于深度学习的突破性进展,但传统的CV算法因其建立的强大数学理论和解决不太复杂问题时的功效而仍然具有魅力。 如今,传统的 CV 算法在我们的日常生活中仍有多种应用,例如智能汽车中的行人检测和交通路标检测,机器人技术中的视觉同步定位和映射(SLAM),电影后处理中的立体视觉 3D 重建 和游戏中的虚拟现实技术。
在我研究生的第一年,我把李教授的这门CV课程作为我的主要课程之一。 李教授致力于通过数学推导和编程实践来启迪我们传统CV算法的强大和魅力。 在本课程中,我们系统地学习了图像处理、相机模型和投影几何的基础知识,以及一些有前途的 CV 应用,包括虚拟现实 (VR) 和立体视觉。
作为本课程的最终作业,我们需要构建一个 VR 场景,并可视化摄像头捕捉到的动态场景。在本报告中,我们将在第2部分简要回顾CV知识,在第3部分介绍赋值要求、赋值的实现和操作细节,在第4部分的预期观察结果。 我们的结论和致谢将显示在第6部分。 详情请查看附录中的代码。
2. 相关知识
2.1 图像处理
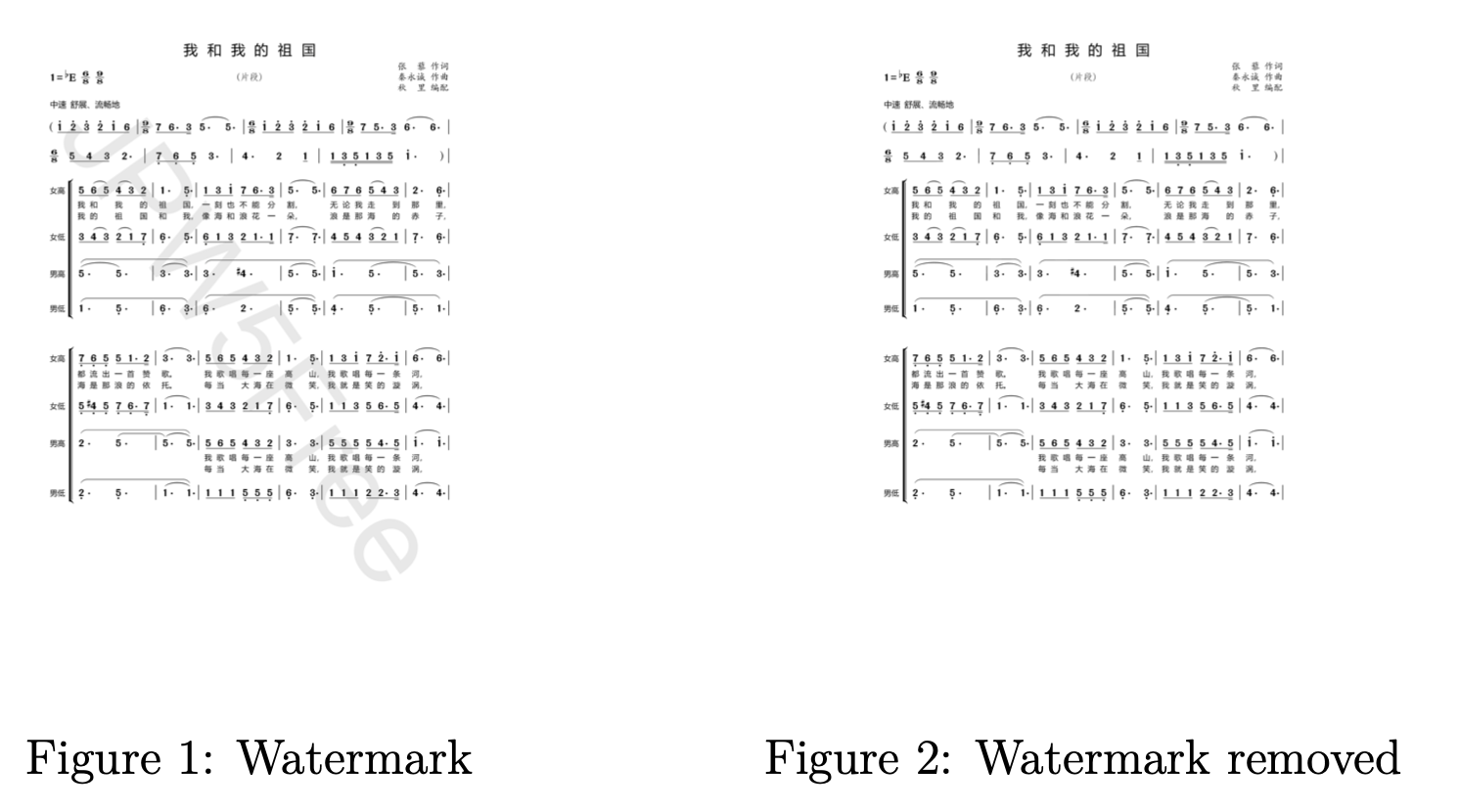
数字图像处理是利用计算机通过一定的算法对数字图像进行处理。 在本课程中,李教授专注于灰度图像中的像素级和拓扑级图像处理和边缘检测。 通过像素级处理技术,我们实现了颜色到灰度的转换,并通过阈值处理实现图像二值化,以简单地去除灰度图像上的简单水印,如图 1 和图 2 所示。此外,采用非拓扑级处理方法 -最大抑制、扩张和侵蚀,我们对去水印后的灰度图进行去噪处理,得到更清晰、更高质量的图像。
对于边缘检测,我们使用 Sobel 算子学习 Canny 边缘检测和 Harris 角检测器,并采用高斯滤波器和非最大抑制来降低噪声。 在实践中,我们使用圆形霍夫变换从检测到的边缘点中提取简单特征,以识别圆形道路交通标志 (RTS),如图 3 和图 4 所示。

2.2 相机模型和投影几何
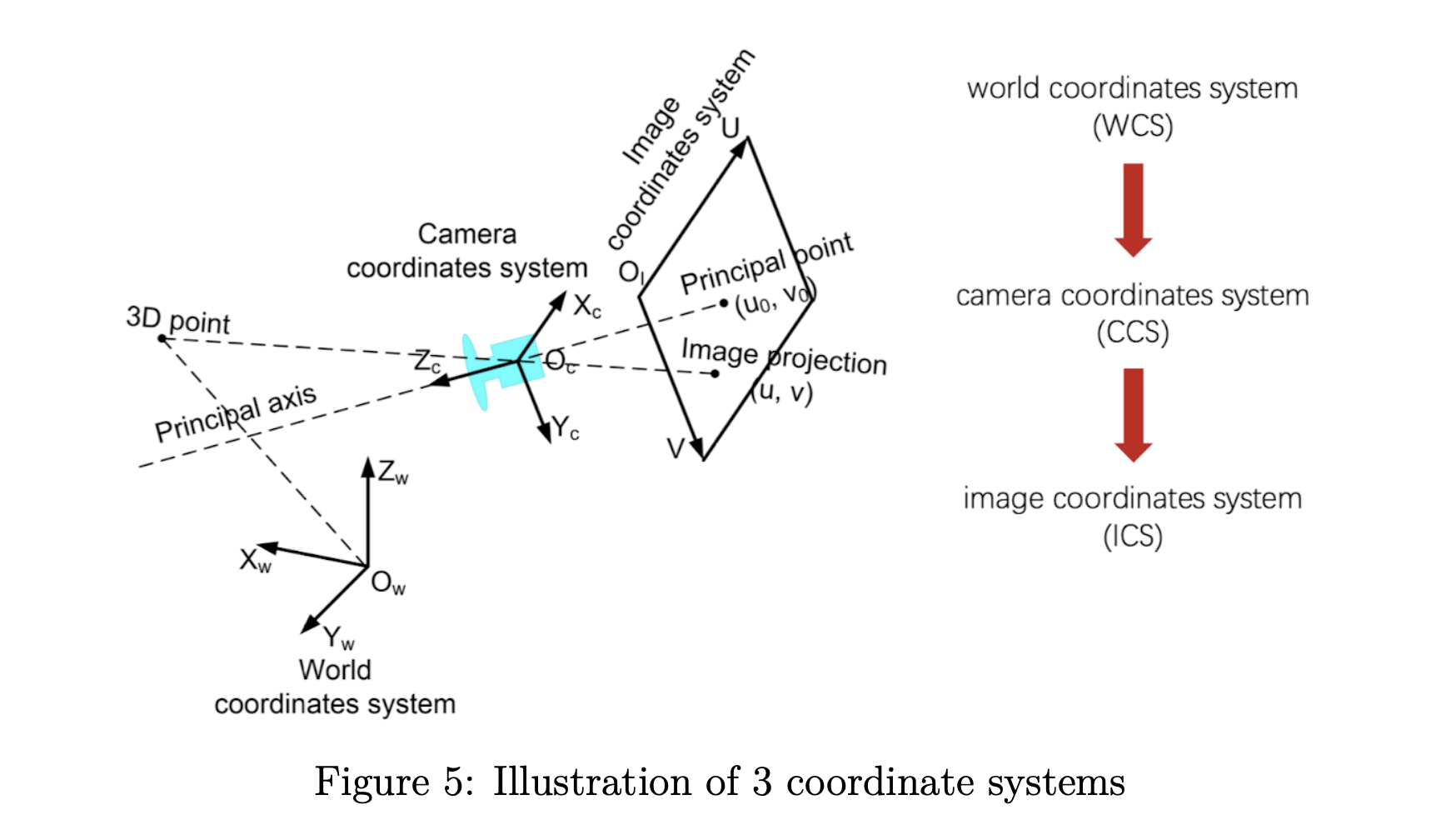
数码相机拍摄图像的过程实际上是一个优化成像的过程,涉及三个坐标系:世界坐标系(WCS)、相机坐标系(CCS)和图像坐标系(ICS)以及这三个坐标系的变换 如图5所示的系统。 WCS是客观三维世界的绝对坐标系。 由于相机被放置在三维空间中,我们需要一个参考坐标系来描述它的位置和其他物体的位置,用。 CCS以相机模型的光心为坐标原点,其轴和轴分别平行于ICS的轴和轴。 我们使用 来表示对象在 CCS 中的位置。 ICS以图像平面的中心为原点,用表示图像上的一个位置。
CCS 可以通过对 WCS 执行旋转操作和平移操作来获得,WCS 以方程1中的矩阵形式表示。 ICS 是通过在等式2中表示为 的相机固有矩阵的投影获得的。
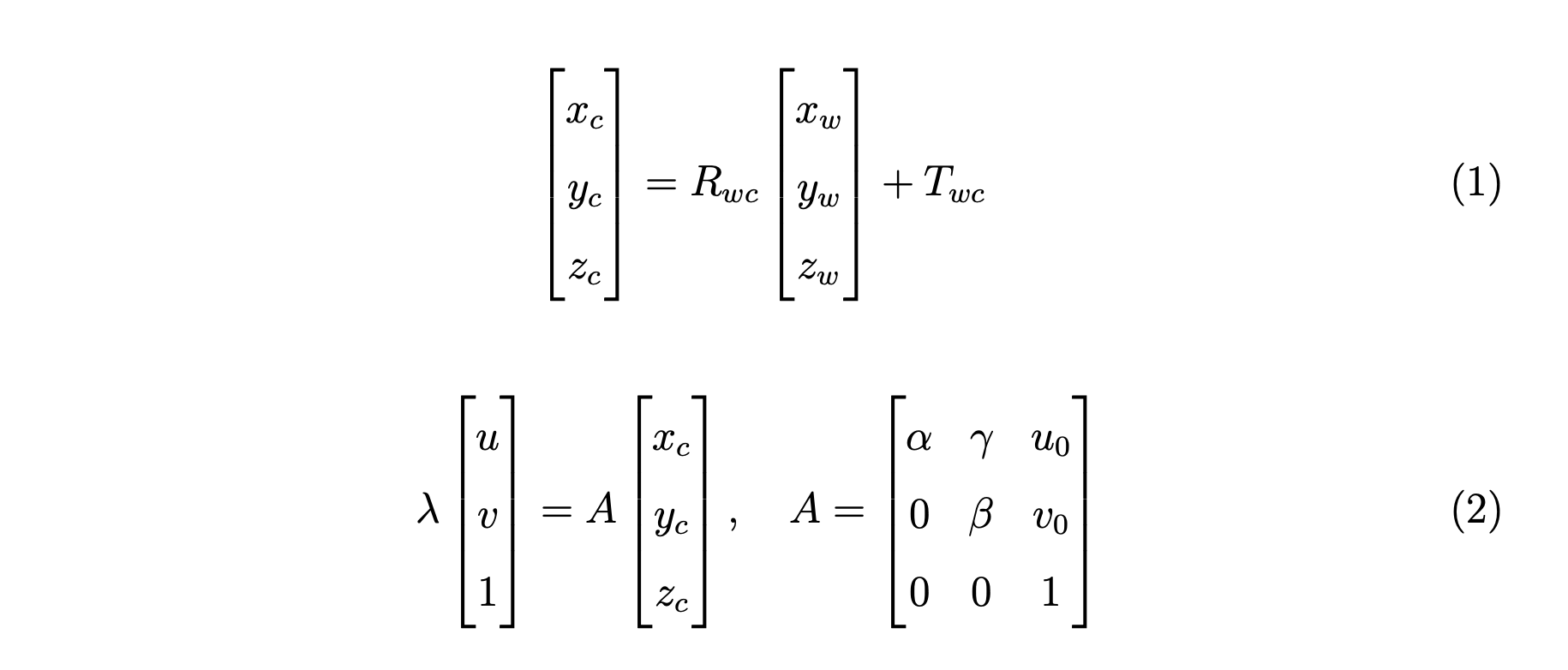
在实践中,我们实现了基于单应性理论的相机标定,对固有参数有两个约束,如图6和图7所示,我们还设法找到了相机固有参数矩阵由不同相机姿势的几张校准照片组成。

2.3 计算机视觉应用
对相机的全面建模和理解使我们能够进一步研究 CV 应用,在本课程中,我们专注于 VR 和立体视觉。
在 VR 中,想法是通过相机模型将现实世界的对象投影到图片上。 但是现实世界不能分解成有限个点,所以我们无法一一求出每个点在图片上的投影。 而是通过相机模型投影后判断图片上的每个像素点是否在物体上,这样会大大减少计算量。 我们将物体分解成有限个不重叠的三角形区域,然后判断一个像素点的投影是否在每个三角形区域内,这样我们不仅可以判断一个像素点的投影是否在物体上, 还要在物体的哪个面上。 图8和图9显示了一个说明性的 VR 实践,其中我们从固定的相机位置(红点)合成彩色立方体对象的 VR 图像。

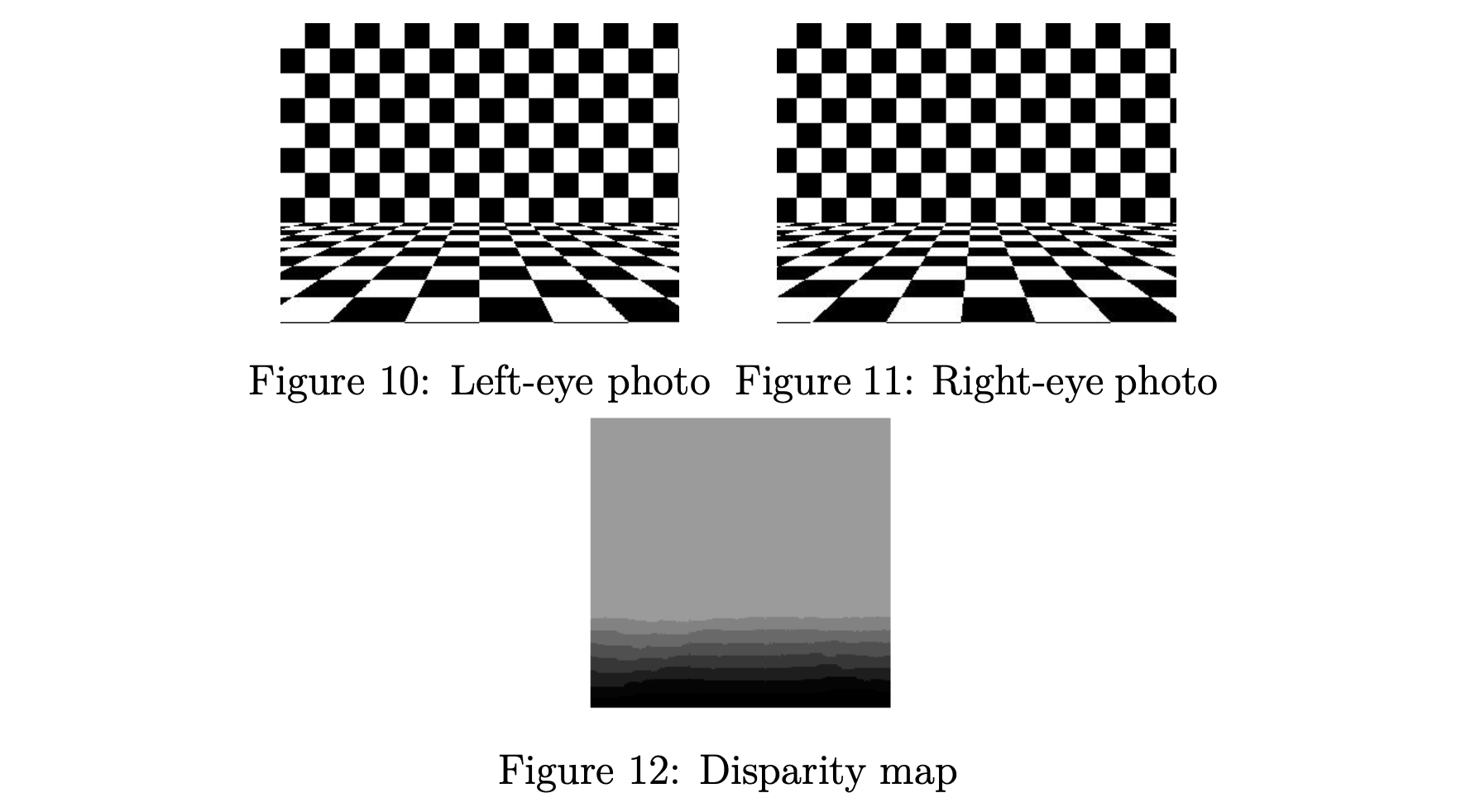
立体视觉需要双目视觉,所以我们需要两个摄像头。 为了在两个相机图像中找到对应的对象,我们使用对极线约束来缩小搜索区域,并使用平方差和(SSD)算法建立对应关系,即匹配具有相同分布的区域。为了简化,我们一般选择保持两个相机之间的轴与水平轴对齐。 立体视觉允许我们测量图像中的距离,也称为场景深度。作为实践,我们使用两张照片建立虚拟场景的立体视差图,如图10、11和12所示。 在视差图中,暗度表示与相机的距离,越暗表示越近。
3. 实验
作为本课程的最终作业,我们需要使用MATLAB构建一个带有简化物体和针孔相机的VR场景,实现相机静止时物体的移动和物体静止时相机的移动,以及 在这两种情况下可视化相机拍摄的场景。
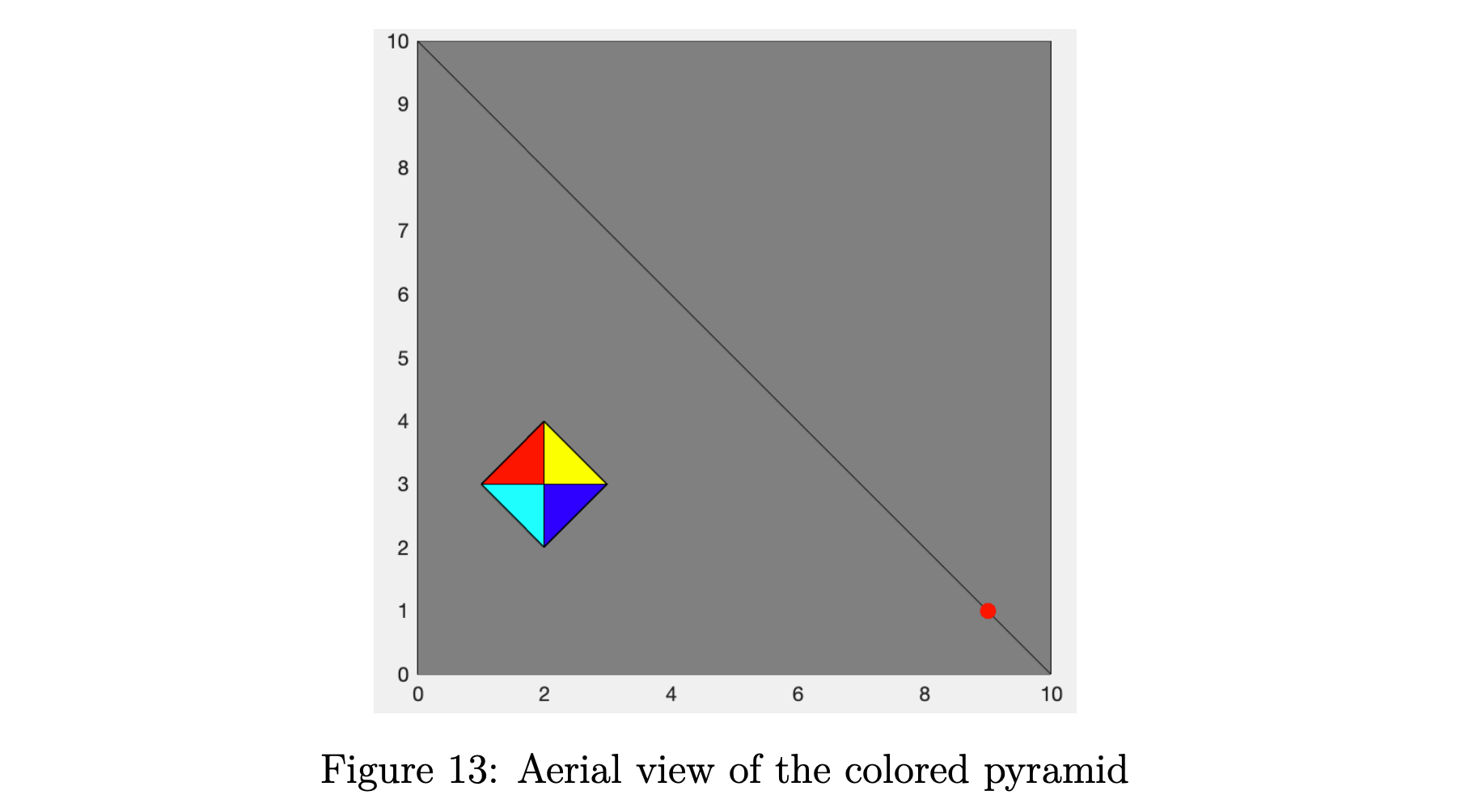
如图 13 所示,我的对象是一个彩色金字塔,可以用 5 个端点 , , 表示 , 和 。 相机放置在红点位置。
3.1 平移
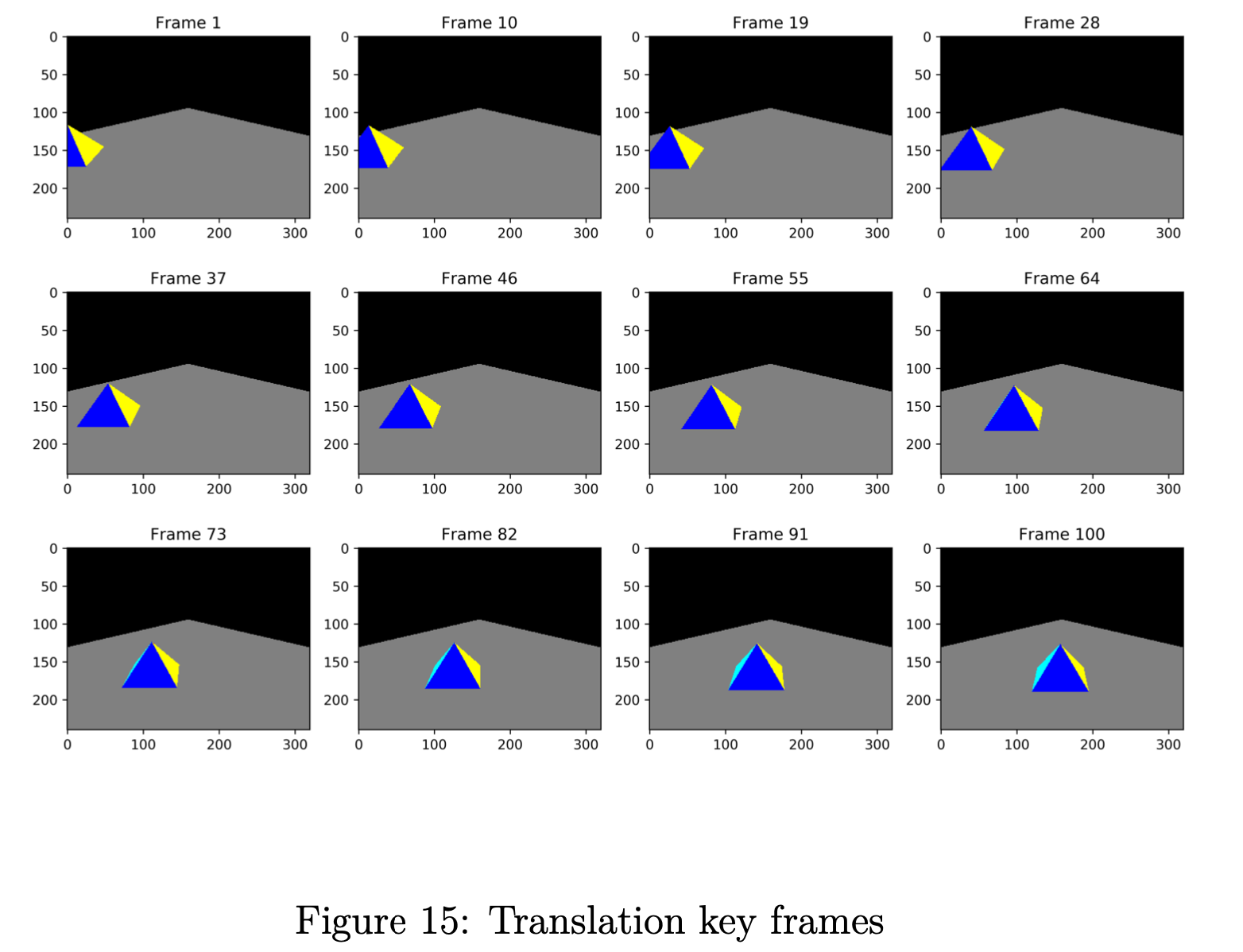
在我们的代码中,金字塔的位置由原始的金字塔坐标和一个初始位置向量组成,其中是5个端点的集合, 、、 和 。 为了添加平移运动,我们只需要添加一个位移向量 ,它是时间 的函数。 在我们的实验中,我们简单地选择从初始位置到世界中心的线性位移。 让我们将金字塔的位置表示为 ,它是 5 个端点的集合,总时间跨度为 。 所以 可以用方程 3 表示。
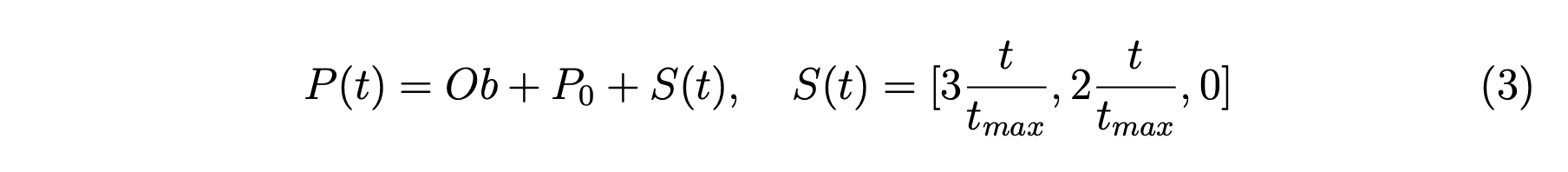
要运行此实验,请进入目录translation 并运行脚本translation.m。 对于每个时刻 ,我们渲染一帧图像并将其存储到子目录frames 中。 然后我们将帧合成为一个名为translation.gif 的 .gif 文件,以便于说明。
3.2 旋转
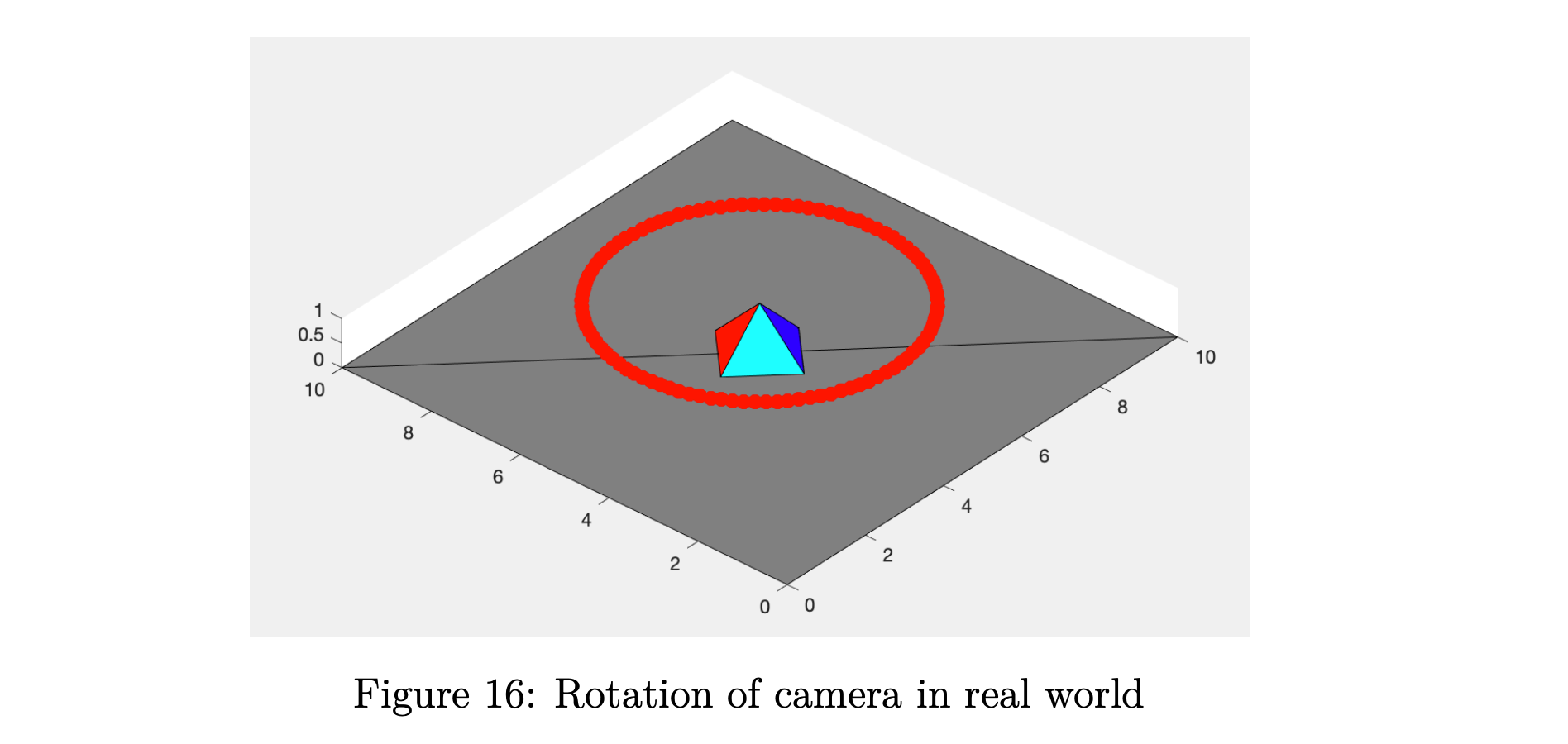
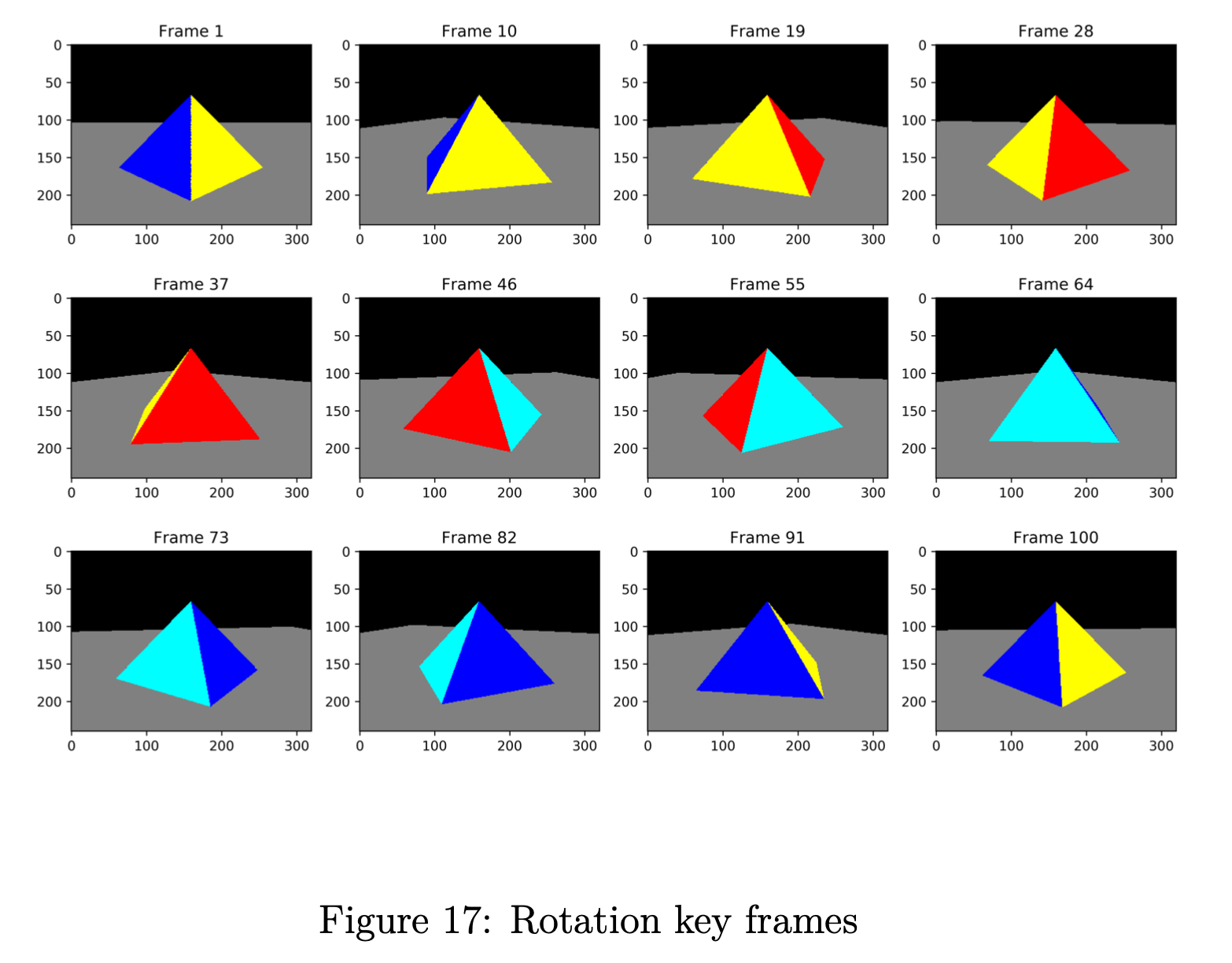
在这部分中,我们将金字塔的位置固定在世界中心 上,我们围绕它旋转相机,同时保持相机指向金字塔。 在我们的代码中,相机位置由变量 控制,我们添加相机的旋转,如方程式 4 所示。 指向角由 、 和 控制,其中 分别是围绕 轴和其他轴的旋转角度。 由于我们的相机仅在 平面内旋转,因此我们的角度控制如方程式 5 所示。
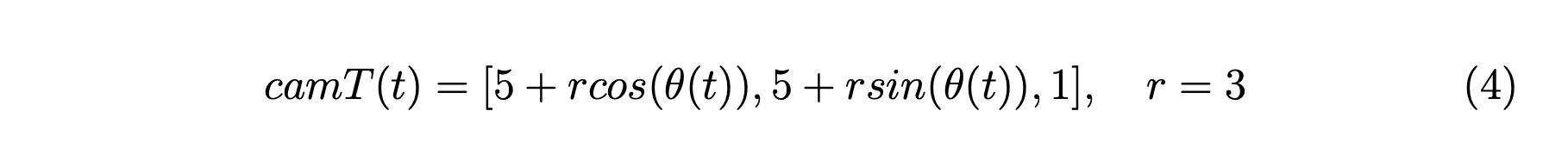
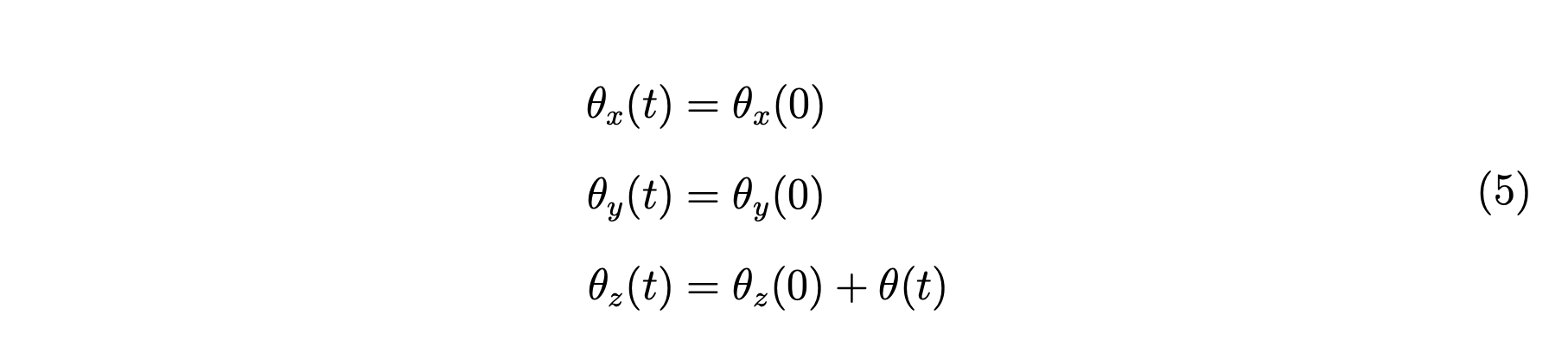
要运行此实验,请进入目录 rotation 并运行脚本 rotation.m。 对于每个时刻 ,我们渲染一帧图像并将其存储到子目录 frames 中。 然后我们将帧合成为一个名为 rotation.gif 的 .gif 文件,以便于说明。
4. 结果分析
我们金字塔的平移如图 14 所示,一些关键帧如图 15 所示。我们相机的旋转如图 16 和一些关键帧如图 17 所示。 在所有图中,红点代表相机位置。 对于每个实验,我们渲染 101 帧,我们的合成 .gif 文件每秒 24 帧,以获得良好的视觉体验。 有关详细信息,请查看代码和我们的 .gif 文件。

5. 总结
在本次作业中,我们使用 MATLAB 建立了一个带有彩色金字塔物体和针孔摄像机的 VR 场景,实现了摄像机静止时物体的移动和物体静止时摄像机的移动,并将捕获的场景可视化 在这两种情况下都由相机拍摄。 这加深了我对VR的理解,也唤醒了我对传统CV算法的进一步兴趣。 在计算的过程中,我们深知CPU的局限性以及GPU并行计算的重要性。
在这门课程中,李教授向我们展示了一些强大的传统CV算法,其中包含的数学基础及其在我们日常生活中的应用,让我印象深刻。 我曾经只知道基于深度学习的CV模型的强大,但现在我也惊叹于传统CV算法的魅力和效率。 在此对李教授的耐心指导、辛勤付出和精心设计的编程实践表示衷心的感谢。