基于统计分析和统计测试的Covid-19数据分析
- 作者:王金元
- 学号:121260910054
- 教师:张莉维
- 日期:2021.12.17
1. 简介
2019年12月,在中国武汉首次发现一种由新型冠状病毒引起的流行肺炎,后来被确定为“新型冠状病毒肺炎”(Covid-19)。2022年12月26日,国家卫生健康委员会发布公告,将新型冠状病毒肺炎更名为新型冠状病毒感染。
截止2023年1月1日,全球已累计报告逾6.60亿名确诊病例,逾669万名患者死亡,目前仍在持续扩散中。为防控新型冠状病毒肺炎疫情,中国政府采取“动态清零”防疫政策。截至12月23日24时,据31个省(自治区、直辖市)和新疆生产建设兵团报告,累计治愈出院病例350117例,累计死亡病例5241例,累计报告确诊病例397195例,累计追踪到密切接触者15377952人,尚在医学观察的密切接触者147724人。经国务院批准,自2023年1月8日起,解除对新型冠状病毒感染采取的《中华人民共和国传染病防治法》规定的甲类传染病预防、控制措施;新型冠状病毒感染不再纳入《中华人民共和国国境卫生检疫法》规定的检疫传染病管理。
基于15个国家和地区的公开新型冠状病毒肺炎死亡统计数据,本报告采用主成分分析法(PCA)、相关因子分析(FAC)和辨别因子分析(DFA)方法,研究新型冠状病毒肺炎疫情的死亡率、人群年龄分布和人群性别分布之间的潜在关系。在此背景下,本报告采用估计测试、充分性测试以及独立性测试等统计学测试方法,尝试确定部分数据的内生分布和分布之间的相关性。
在本文中,我们将聚焦于以下三个部分:
- 数据处理:观察数据格式,总结归纳数据规律,使用Python脚本,从给定的多个xlsx文件中,自动化读取数据;
- 统计分析:采用主成分分析法(PCA)、相关因子分析(FAC)和辨别因子分析(DFA)方法,研究新型冠状病毒肺炎疫情的死亡率、人群年龄分布和人群性别分布之间的潜在关系;
- 统计测试:采用估计测试、充分性测试以及独立性测试等统计学测试方法,尝试确定部分数据的内生分布和分布之间的相关性。
2. 数据处理
经过观察数据,我们选择使用的数据有:
- 每个国家2022年的人口统计数据:按照年龄段、性别区分
- 每个国家2020-2022年累计新型冠状病毒肺炎死亡统计数据:按照年龄段、性别区分
2.1 统一化处理
由于葡萄牙(Portugal)、韩国(Republic of Korea)和罗马尼亚(Romania)缺失部分统计数据,我们选择排除掉这三个国家的数据。
由于每个国家对年龄段的划分不尽相同,我们经过分析和取舍,决定将年龄段进行统一划分,其中美国(USA)和奥地利(Austria)的年龄段划分较为特殊,因此我们处理过的数据或与真实情况有偏差。
对于每个国家的数据,我们按照以下维度进行分类统计:
- 年龄段:40岁以下,40-60岁,60岁以上
- 性别: 男性、女性、两种性别
- 方面:死亡人数、人口总数、每千人死亡数
因此,我们共有27栏数据,为以上三个维度组合得到。
2.2 归一化处理
为了保证数据之间的量级相同,我们进行了以下归一化处理:
- 对于每个国家,我们将各年龄段、各性别的死亡人数除以该国各年龄段、各性别的死亡人口总数,得到各年龄段、各性别的死亡百分比;
- 对于每个国家,我们将各年龄段、各性别的人口数据除以该国各年龄段、各性别的总人口数,得到各年龄段、各性别的人口分布百分比;
- 对于每个国家,我们将各年龄段、各性别的死亡人数除以该国各年龄段、各性别的相应的人口数,再乘以1000,得到各年龄段、各性别的每千人死亡数,然后对所有国家的各年龄段、各性别的每千人死亡数进行归一化处理。
2.3 发展程度标签
我们根据发展程度,手动为每个国家打上“发展中国家”和“发达国家”的表情,以备后续辨别因子分析使用。除了乌克兰(Ukraine)和摩尔多瓦(Moldova)两个国家为“发展中国家”,其余国家均为“发达国家”。
3. 统计分析
在本节中,我们将按以下顺序对数据进行分析:
- 主成分分析;
- 判别因子分析;
- 对应因子分析。
3.1 主成分分析(PCA)
主成分分析 (PCA) 是一种流行的技术,用于分析每次观察包含大量维度/特征的大型数据集,在保留最大信息量的同时提高数据的可解释性,并实现多维数据的可视化。
形式上,PCA 是一种用于降低数据集维度的统计技术。这是通过将数据线性变换到一个新的坐标系中来实现的,在该坐标系中(大部分)数据的变化可以用比初始数据更少的维度来描述。
在本实验中,我们将选择 6 列数据作为特征并使用 PCA 将数据的维数减少到2维。我们将找到数据中最大方差的2个主成分,并尝试解释。
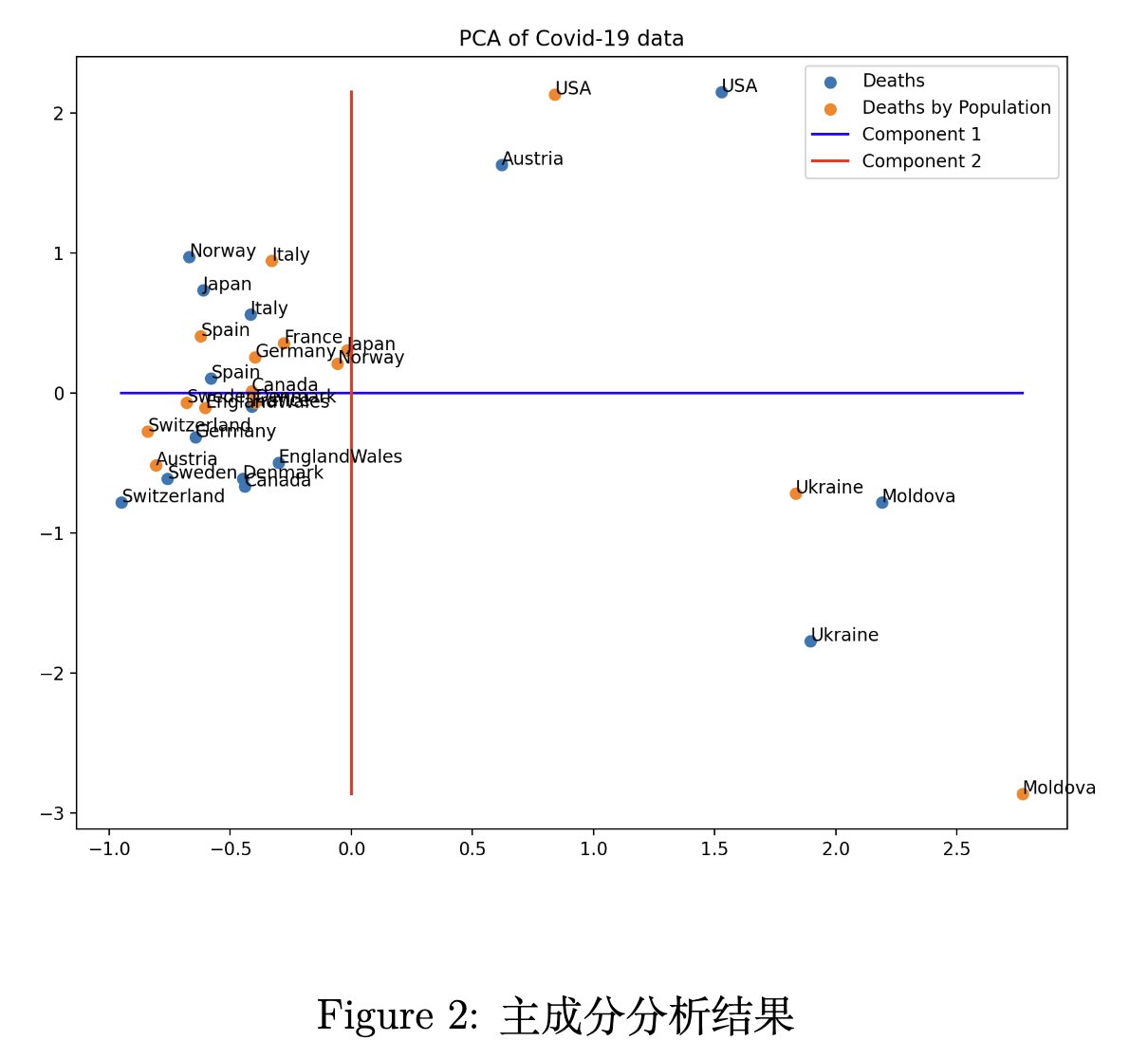
我们的代码如图所示,结果如图2所示。我们发现:
- 第一个组成部分代表 60 岁以上或以下老年人的“死亡”,不分性别。
- 第二个组成成分代表按“性别”区分的“40-60”岁人群的“死亡”。
我们进一步将“每千人死亡百分比”数据投影到前 2 个主成分并绘制结果,结果以橙色圆点显示。我们发现:
- 美国、奥地利、乌克兰和摩尔多瓦在第二个轴上表现比较显著,美国和乌克兰分别是两个极端。
- 瑞士和摩尔多瓦在第一个轴上表现比较显著,分别是两个极端。
3.2 辨别因子分析(DFA)
判别分析在因子方法中具有特殊的地位,因为它可以赋予“学习”阶段以意义。DFA的使用情况如下:
- 我们有定量数据(对 n 个人的 p 测量);
- 我们还有定义 k 个类别的定性数据;
- 我们知道,对于每个个体他属于哪一类
目标是“教”计算机识别任何新个体并将其分类为 k 个类别(具有最大可能的可靠性)。
在本实验中,我们将“发达国家”标记为 1,将“发展中国家”标记为 0。我们将使用 6 列数据作为特征,并使用判别因子分析将国家分为两类,我们的函数代码如图所示。
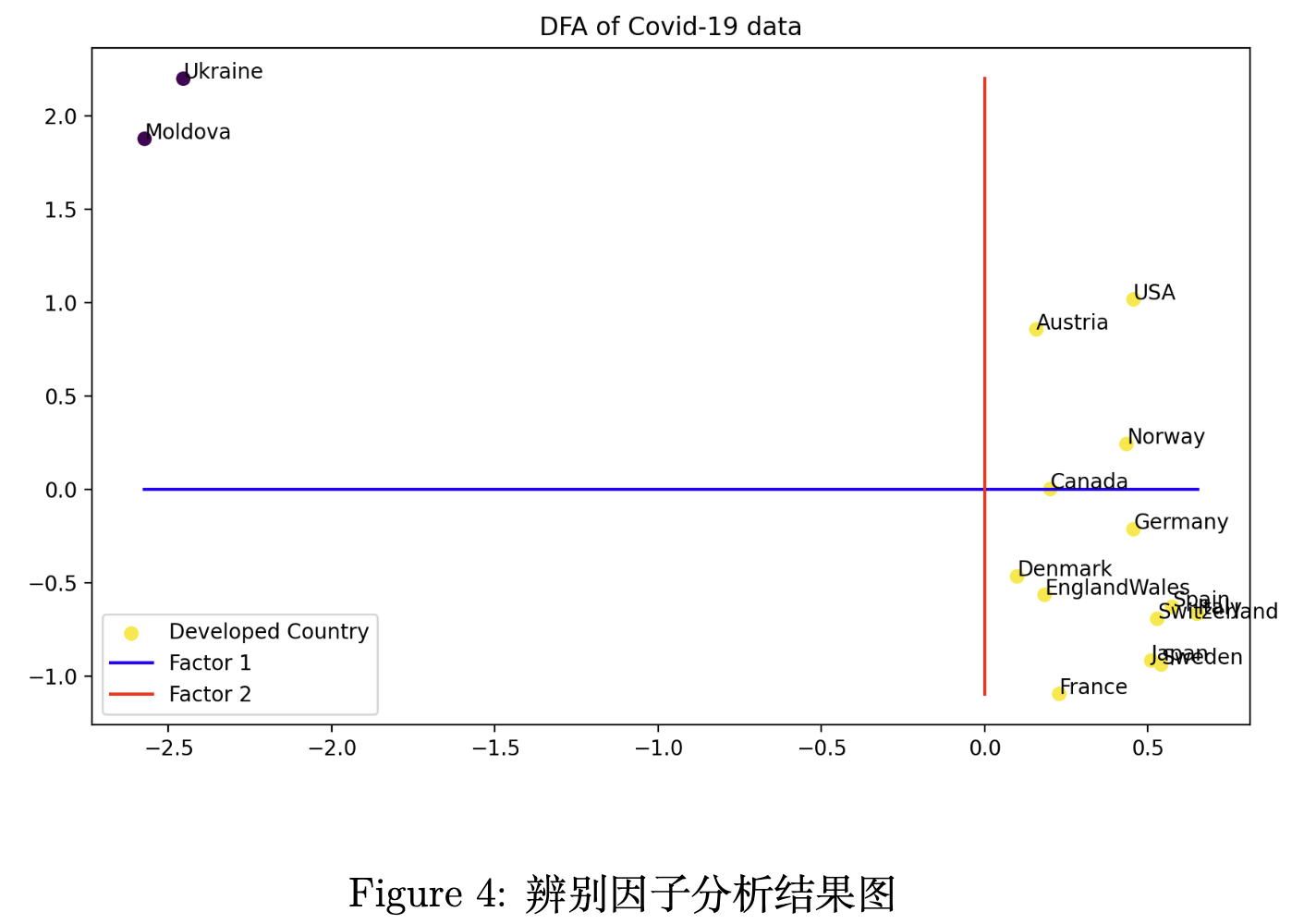
我们可以看到,两类国家被纵轴很明显地分开了,这说明我们找到的第一个因子可以很好辨别“发展中国家”和“发达国家”的死亡比例分布的差异。
3.3 对应因子分析(FAC)
行为者对应分析 (FAC) 是一种用于分析分类数据的统计方法。 它是主成分分析 (PCA) 对分类数据的推广。它用于减少列联表的维数,并识别数据的潜在结构。在本实验中,我们将尝试找到数据中最大方差的 2 个潜在因素。
我们的函数代码如下所示,我们的实验结果如图所示。
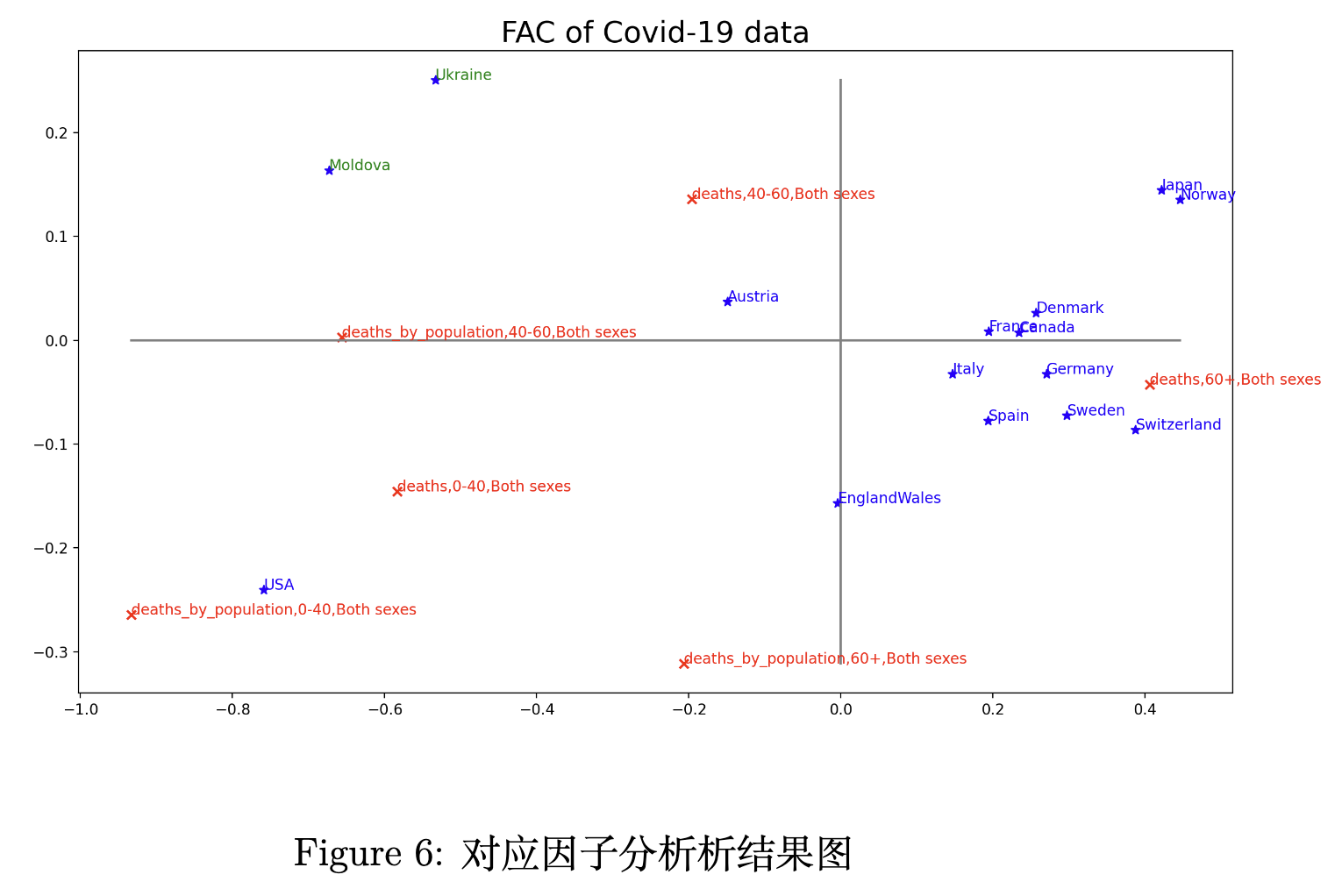
我们可以得出以下结论:
- 对于日本、挪威、法国、加拿大、意大利、德国、丹麦、西班牙、瑞典、瑞士和英格兰威尔士,这些国家和“60岁以上死亡人数”距离较近,说明这些国家高龄人群死亡人数较多,这和这些国家属于“发达国家”的现状以及我们的直觉是比较符合的;
- 美国年轻人的“每千人死亡率”较高,它虽然是发达国家,但可能医疗资源多为富人服务,年轻人可能在医疗资源的获得性上不占优势,因此死亡率较高;
- 对于乌克兰和摩尔多瓦,这两个国家为“发展中国家”,中年(40-60岁)人口死亡占比较大,中年人口“每千人死亡率”也比较高。
4. 统计测试
在本节中,我们将按以下顺序对数据进行统计检验:
- 估计测试(包括均值估计和标准差估计);
- 充分性测试;
- 独立性测试。
4.1 估计测试(均值)
我们选择第一栏数据进行估计测试,计算出均值为24.22。我们的假设是:: 均值为,我们采取间隔采样的方法,从20到30取样,间隔为1.
我们使用st.ttest_1samp()函数来计算p值,选定的alpha=0.05,当p值小于0.05的时候,我们拒绝H_0,否则,我们不拒绝H_0。
测试结果如上所示,我们可以看到,随着显著性等级(significance level)的提高,区间的精度在不断提高。
4.2 估计测试(标准差)
我们选择第一栏数据进行估计测试,计算出标准差为2.50。我们的假设是:
我们使用卡方测试(\chi^2)来确定标准差所在的区间,代码如图下所示。
测试结果如图下所示,我们可以看到,随着显著性等级(significance level)的提高,区间的精度在不断提高。
4.3 充分性测试
我们以奥地利的两性人口的年龄分布情况进行检验,分布如图下所示。
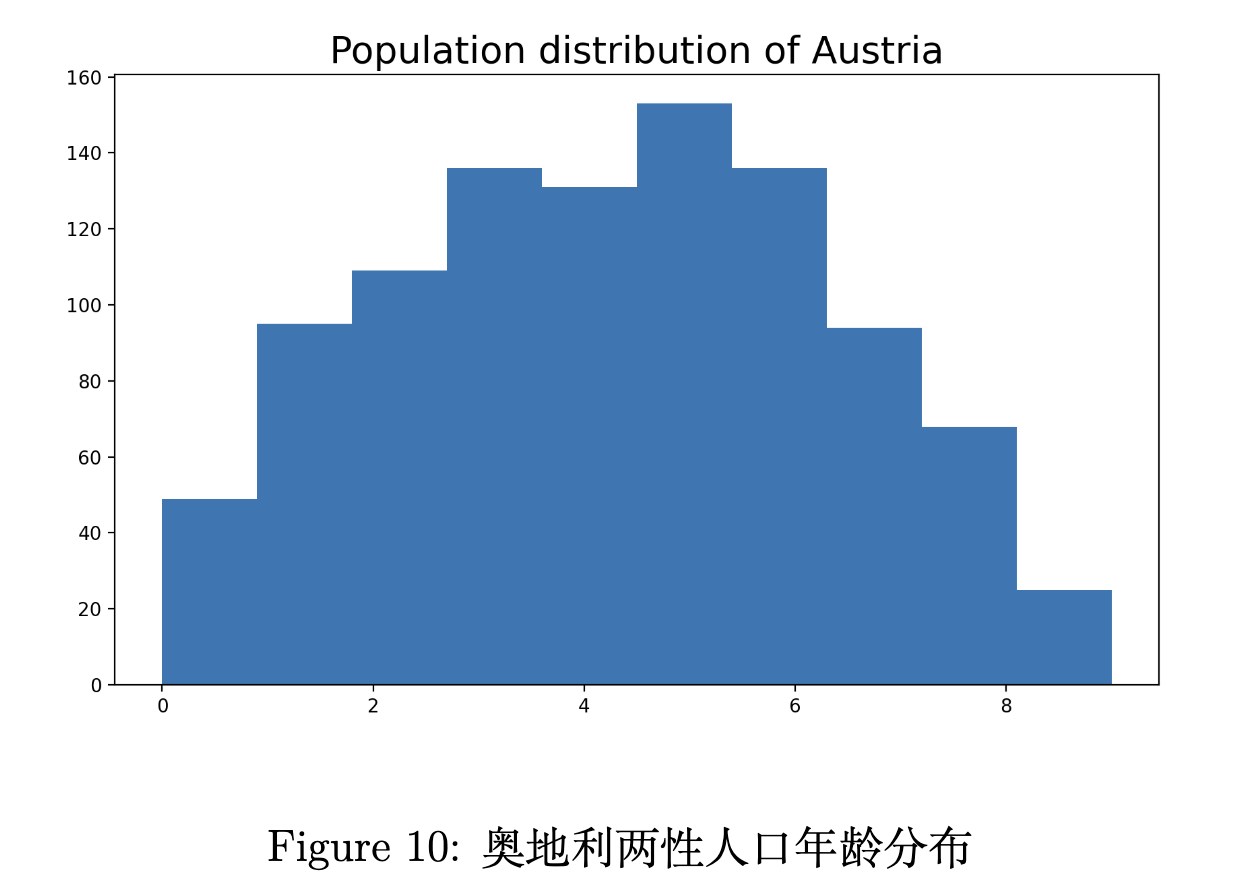
虽然这个分布看起来像是一个正态分布,我们测试了均匀分布、正态分布、泊松分布和指数分布。 但是不幸的是,如下所示, 这些测试的p值都远小于0.05,因此我们不得不拒绝显著性等级(significance level)为0.05下的所有假设。
4.4 独立性测试
我们想研究这15个国家的中年人(40-60岁)和老年人(60岁以上)的“每千人死亡率”的分布之间是否遵循同一个分布,如图下所示。
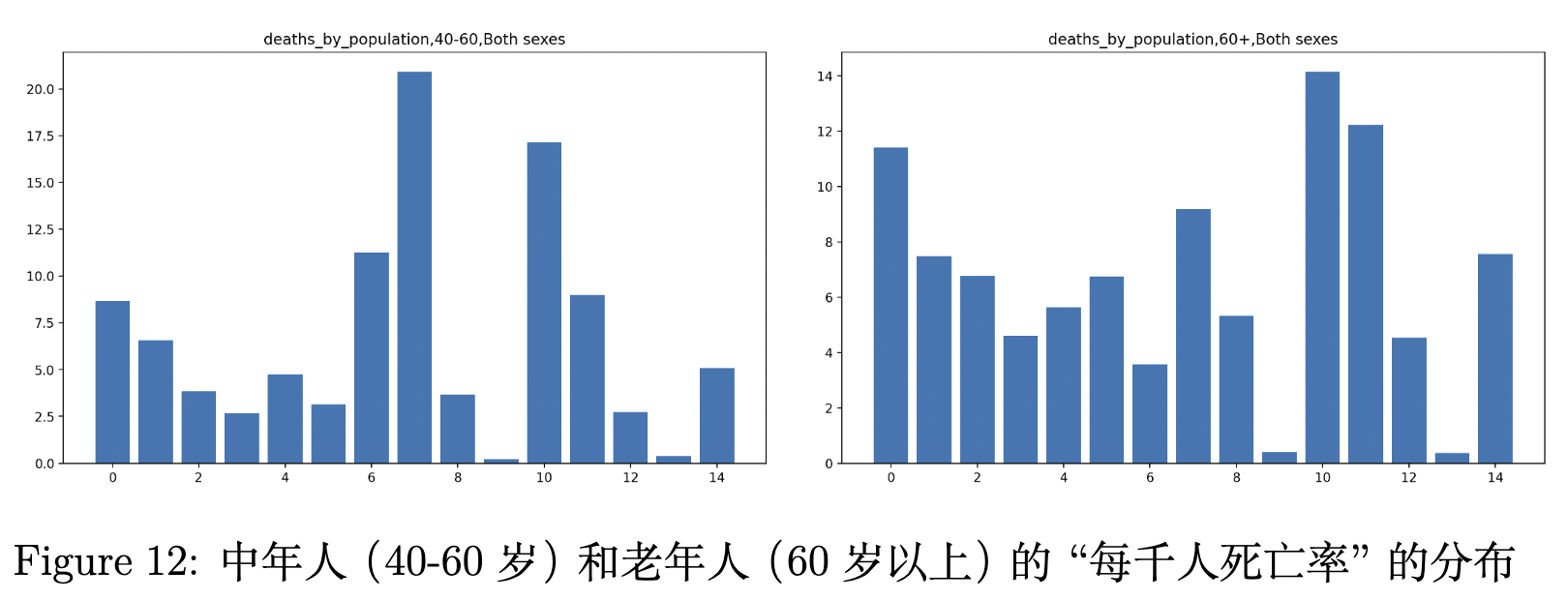
我们的假设是:“这两个分布遵循同一个分布法则”,我们选择的显著性等级(significance level)为。
如上所示,我们使用计算得到p值为,大于,因此我们不能拒绝。
5. 结论
在本项目中,我们针对15个国家的新型冠状病毒肺炎死亡统计数据进行了数据处理、统计分析和统计测试,将课程上所学的主成分分析法、辨别因子分析法和对应因子分析法投入实际应用中,并得出了有趣的结论。我们还对真实数据进行估计测试、充分性测试和独立性测试,对相关知识有了更深刻的理解。