认知实习报告
第一章 项目介绍
1.1 - 实习背景
上海交大-巴黎卓越工程师学院(SJTU-Paris Elite Institute of Technology, SPEIT),依托上海交通大学优势学科和办学条件,引进法国先进的工程师培养理念和优质教学资源,旨在培养复合型、应用型、国际化的工程师。 有远见、适应经济社会发展的优秀工程技术人才和企业领导人才。 在SPEIT,运营实习安排在第三学年末,以评估前三年预备阶段的学习成果。 今年夏天,我以算法研究工程师的身份开始了在 Evoco Labs 的运营实习。
Evoco Labs于2018年成立于Palo Alto(美国硅谷),2019年总部迁至上海。成员来自Facebook、西门子、苹果、花旗等公司,公司还汇集了世界顶尖大学的人才, 包括加州大学伯克利分校、斯坦福大学和香港中文大学[1]。 团队专注于人工智能与消费级医疗设备的深度融合与优化,致力于打造更智能、更舒适的可穿戴设备。
随着世界人口老龄化,听力损失困扰着越来越多的人,助听器市场不断扩大。 然而,目前助听器市场上的产品价格居高不下,用户体验也没有想象中那么好。 许多助听器产品只是声音放大器,它只是简单地放大噪音和人的声音。 一些昂贵的助听器具有传统的噪声消除功能,但传统方法并不总是能达到预期的效果,尤其是在复杂的声学环境中。 为了解决这个问题,Evoco致力于打造一款设计优雅、价格亲民、人工智能降噪的助听器[1]。
在实习算法研究工程师期间,我参与并领导了一个基于递归神经网络(RNN)的语音增强(SE)项目。 后来,我们的团队提出了一种通用算法,可以在基于 RNN 的模型上实现极低延迟,并证明了其在降低输入延迟方面的卓越性能。
1.2 - 项目背景
语音分离是将目标语音与背景干扰分离的任务,背景干扰可能包括非语音噪声、干扰语音以及房间混响 [2]。 语音增强(或降噪)是语音分离的一个高级且长期的目标,具有广泛的实际应用,例如自动语音识别 (ASR) 和助听器。 去噪的一般任务是应用不同的增益集以增强目标语音并降低语音分离后的背景噪声。 近年来,受深度学习空前成功的启发,许多基于 RNN 的模型 [3] [4] 被设计用于此任务,其中一些模型取得了显着的性能。 然而,基于 RNN 的模型在极低延迟语音增强方面存在很大困难,这对其消费级应用构成了巨大障碍。 当前的低延迟深度学习模型通过简单的网络设计大大减少了模型处理时间。 然而,由于 RNN 每次处理一帧带噪声的语音 [3],理论上,帧长是造成延迟的必然原因,模型处理时间也是如此。 因此,目前的低延迟模型还不能满足消费级应用的极端要求,尤其是助听器,可感知的延迟会导致长期使用的不适[1]。
1.3 - 项目大纲
在这个项目中,我们首先构建了一个精简的基于 RNN 的语音增强系统,并找到了最佳的超参数来优化它。 后来,我们提出了一种权衡算法来显着减少 RNN 的输入延迟。 实现后,我们设计了实验来证明我们提出的算法的有效性。
第二章 背景知识
2.1 - 数字信号处理
数字音频是一种使用数字方式记录、存储、编辑、压缩或播放声音的技术。 信号被记录在无数个不连续采样的数字点中,以还原连续信号的波形。 一秒钟内的采样点数称为采样率。 采样率越高,数字音频越能还原连续波形。 每个采样点都以相同的数字类型存储,例如int16和float32。
2.1.1 WAV格式
WAV是最常见的声音文件格式之一,是由微软公司开发的标准数字音频文件。 符合资源交换文件格式(RIFF)规范,能保证声音不失真。所有的 WAV 都有一个文件头 [5],这是音频流的编码参数。 在文件的前 44 个字节放置一个 WAV 文件头,以便播放或编辑者可以轻松掌握文件的基本信息。 它的内容以chunk为最小单位,每个chunk的长度为4字节。

在C/C++中读取WAV文件时,我们需要读取文件的前44个字节来获取文件头。 通过分析文件头,我们知道了WAV文件的基本信息,包括采样率、文件长度和数据类型。 那么我们就可以根据它的数据类型和文件的长度来读取数据了。
2.1.2 信噪比
在 DSP 中,信噪比 (SNR) 是一种将所需信号的电平与背景噪声电平进行比较的量度。 SNR 定义为信号功率与噪声功率之比,通常以分贝表示。
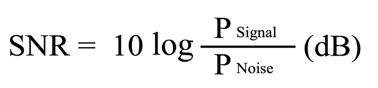
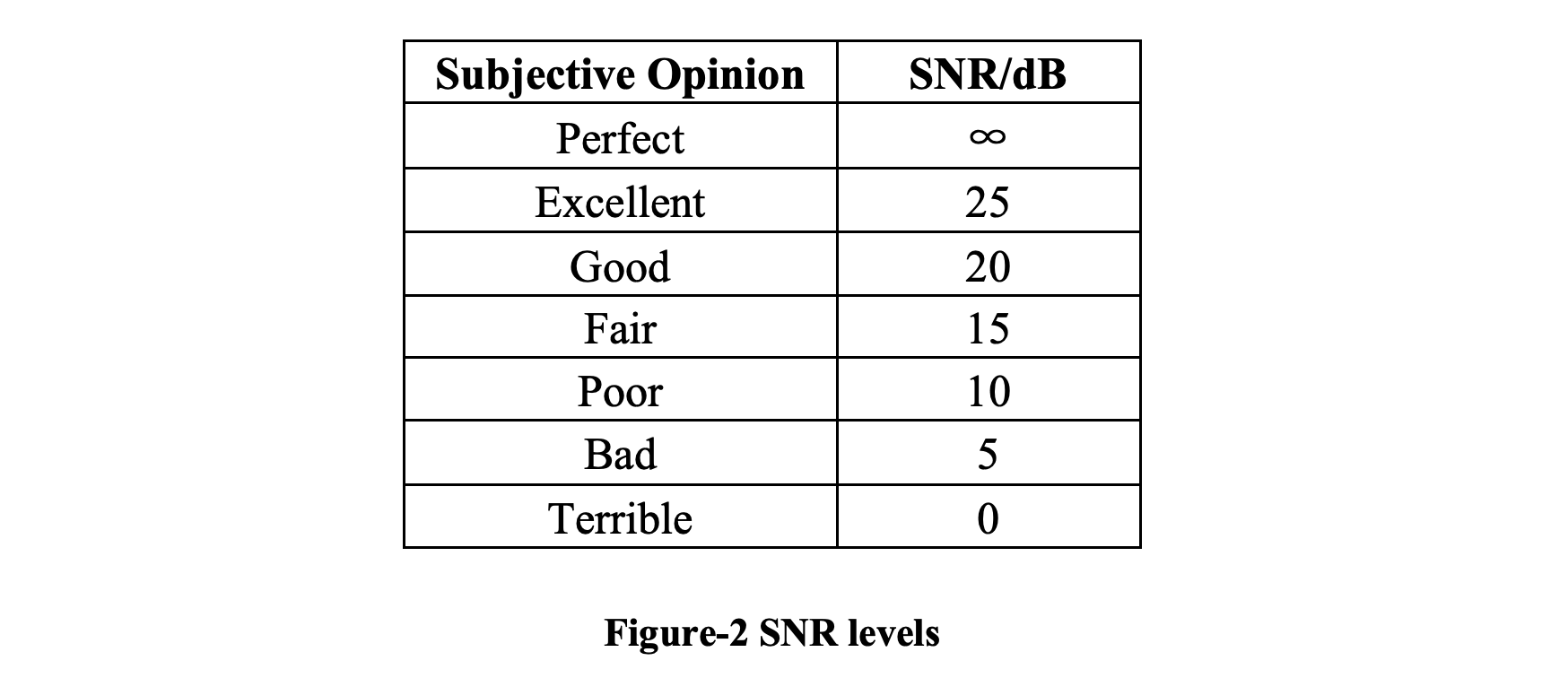
比率大于 0 dB 表示信号多于噪声。 SNR及其对应的主观意见大致可分为以下几个等级:
2.1.3 傅里叶变换
傅立叶变换 (FT) 是一种数学变换,可将时间函数分解为其组成频率。 相应地,傅立叶逆变换 (IFT) 从其频域表示中数学合成原始函数,正如傅立叶反演定理所证明的那样。
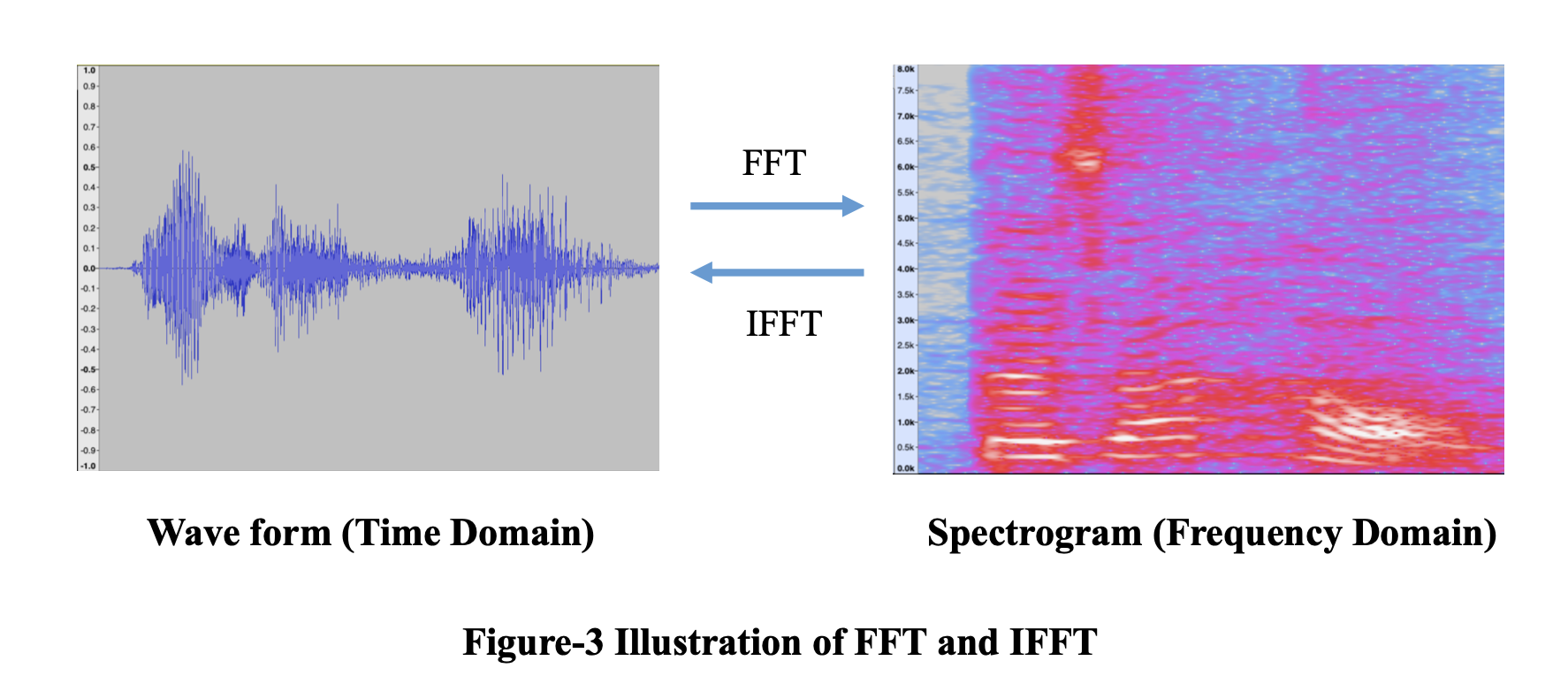
通常,数字信号由等距样本的有限序列表示。 离散傅里叶变换 (DFT) 是一种数学工具,用于将时间实值函数的等间隔样本的有限序列转换为复值频率函数的等间隔样本的相同长度序列。 快速傅里叶变换(FFT)是一种高效的 DFT 算法,可以在 O(n*logn) 时间内完成。 在DSP中,FFT是最常用的分析方法。 我们应用 FFT 将信号从时域变换到频域。 对提取的频率特征进行分析和处理。 然后我们应用反向 FFT (IFFT) 将处理后的特征转换为数字信号。
2.1.4 频率泄漏
FT 研究无限时域和无限频域之间的关系。 但是,用计算机实现DSP时,不可能对无限长的信号进行测量和计算,而是要花有限的时间段进行分析。 FFT以时间段为输入,进行周期扩展处理,得到一个虚拟的无穷大信号,然后可以对信号进行傅立叶变换。
漏频是由扩展信号的不连续性引起的,因为在两个周期的交界处会有垂直信号。 FT会将垂直信号分解成不同频率的无限次谐波,这会妨碍我们准确提取这一帧的频率信息。 这些谐波还会损害 IFFT 的输出质量:会出现离散的全频白噪声。因此,我们需要应用一些窗口函数来消除不连续性。 常用的窗有矩形窗、汉宁窗、汉明窗、费耶尔窗和高斯窗。
在这个项目中,我们使用一种称为 Vorbis 窗口的高斯窗口 [6],其定义为:(N 是帧大小)
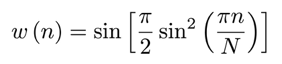
2.1.5 语音评估指标
一般来说,有两种常用的语音评估指标,PESQ [7] 和 STOI [8]。
语音质量感知评估(PESQ)算法是一种客观的语音质量测量方法。 PESQ 的详细描述及其预期用途可在 ITU-T Recommendation P.862 [7] 中找到。PESQ 的开发是为了预测端到端网络质量的平均意见得分 (MOS),由一组听众 [9] 判断。 每个听众通过选择五个选项之一来评价“连接质量”:“差”、“差”、“一般”、“好”和“优秀”。 然后将数字分配给这些标签(分别为 1、2、3、4 和 5),并将数字的平均值作为 MOS。 基本上,PESQ 通过比较处理后的语音文件和原始语音文件来预测主观 MOS 分数。
短时目标清晰度 (STOI) 测量显示了噪声和时频处理语音的清晰度的相关性 [8]。 它给出一个介于 0 和 1 之间的浮点数来表示降级语音的质量,越高越好。 与其他倾向于依赖整个句子的全局统计数据的传统可懂度测量相比,STOI 基于更短的时间段(386 毫秒)。
在这个项目中,我们使用 PESQ 作为指标来评估我们的模型。
2.2 - 深度学习
在本节中,我将介绍循环神经网络 (RNN) 的基础知识,尤其是长短期记忆 (LSTM) [11] 和门控循环单元 (GRU) [12]。
2.2.1 循环神经网络
RNN 是一种处理序列数据的神经网络。 可以将 RNN 视为同一网络的多个副本,每个副本将一条消息传递给后继者 [10]。 在过去几年中,将 RNN 应用于各种问题取得了令人难以置信的成功:语音识别、语言建模、机器阅读理解……
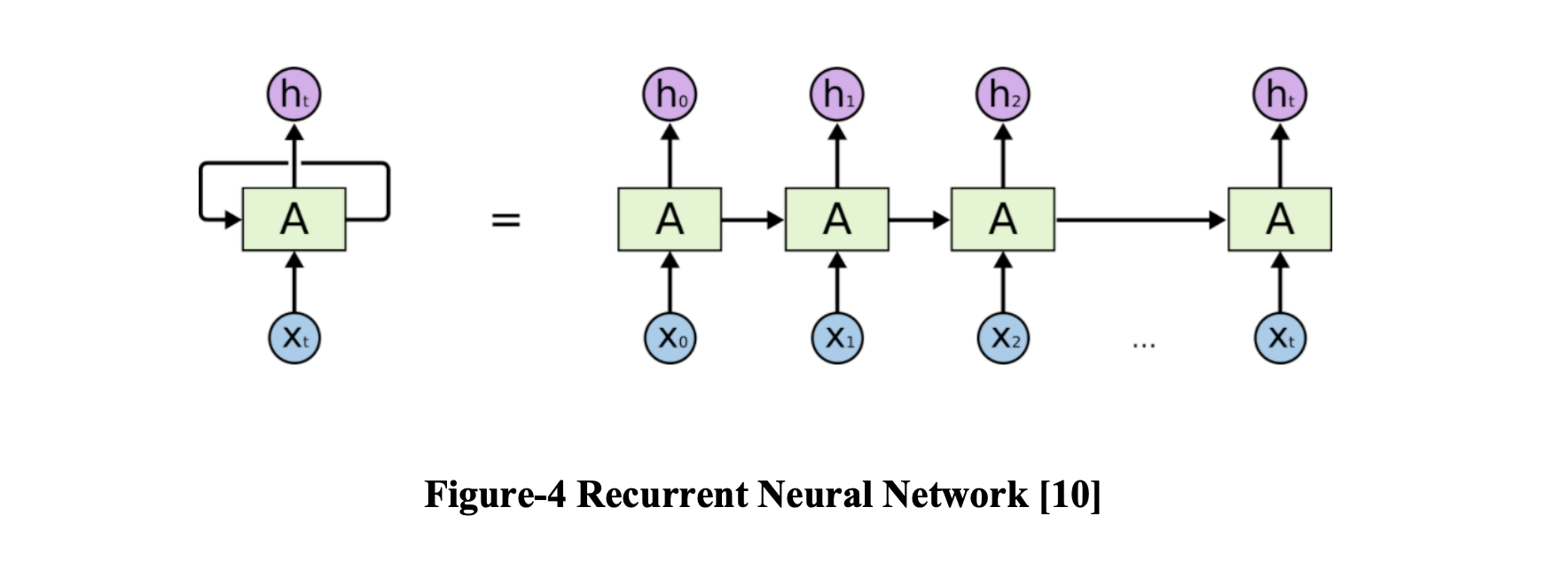
2.2.2 长短期记忆网络
随着信息差距的扩大,传统的 RNN 无法学习长期依赖关系。 为了解决这个问题,引入了长短期记忆网络 (LSTM) [11] 来学习长期依赖关系。
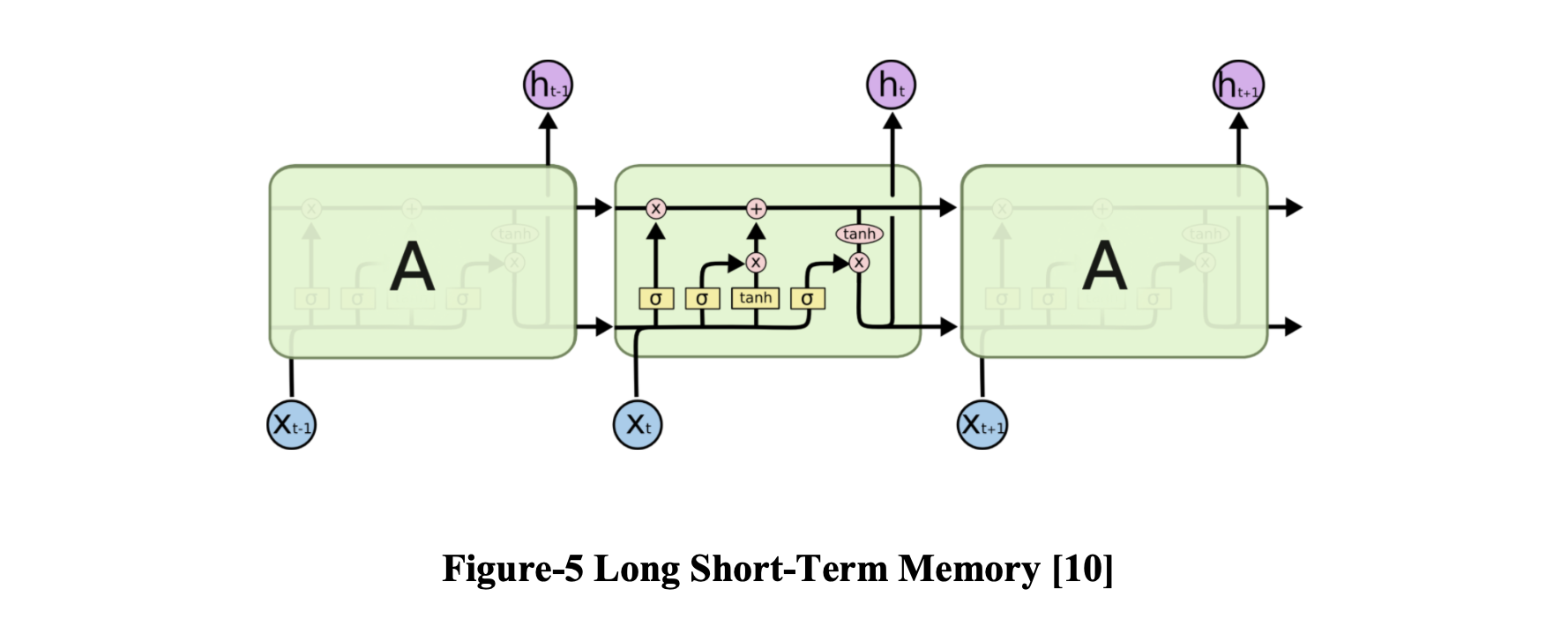
LSTM 的关键是细胞状态,即贯穿图表顶部的水平线。 细胞状态有点像传送带。 它直接沿着整个链条运行,只有一些次要的线性交互。 每个输入通过 LSTM 的输出称为隐藏状态。LSTM 具有由三个门组成的机制:输入门、遗忘门和输出门。 输入门决定输入状态的重要程度,遗忘门决定之前的状态对当前状态是否重要,输出门判断当前状态是否值得输出。
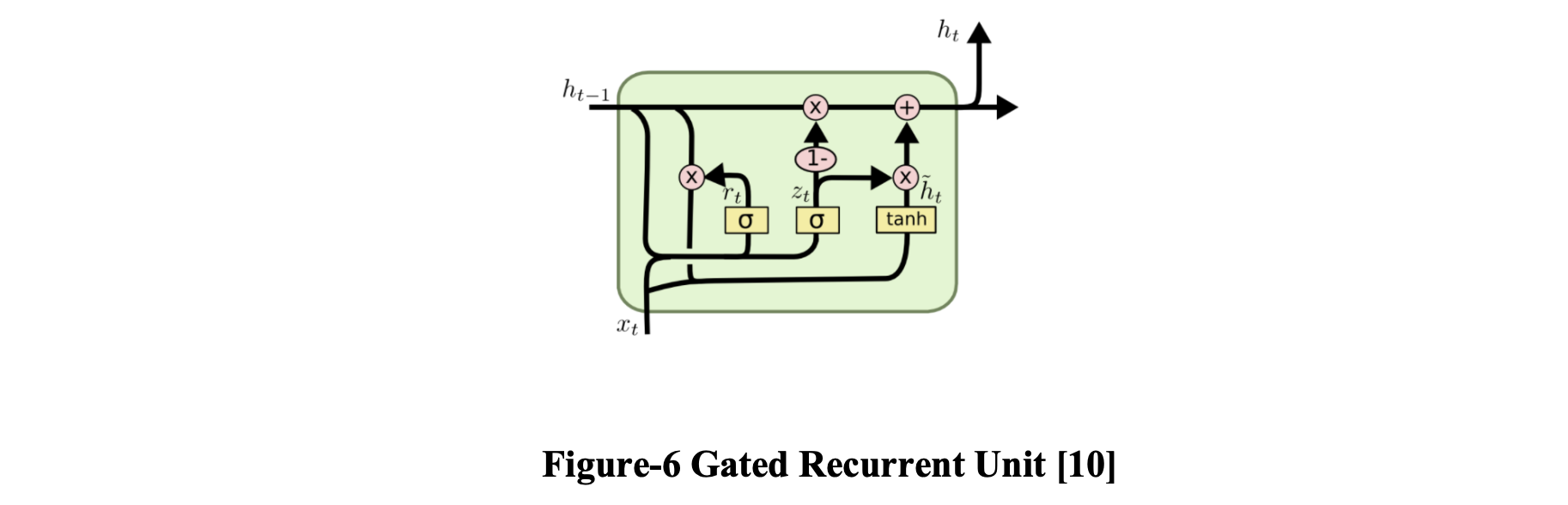
2.2.3 门控循环单元
为了简化 LSTM,Cho 等人引入了门控循环单元 (GRU)。 2014 年 [12]。 它将遗忘门和输入门组合成一个更新门,并合并单元状态和隐藏状态。 由于生成的模型比标准 LSTM 更简单,因此越来越受欢迎。
第 3 章 精简版语音增强系统
在过去的两个月里,我们构建了一个基于精简版 RNN 的语音增强系统,包括数据生成器、模型训练和评估。
3.1 - 深度学习架构
至少从 70 年代开始,噪声抑制一直是人们关注的话题。 尽管质量有了显着提高,但高层结构基本保持不变 [3]。 某种形式的频谱估计技术依赖于噪声频谱估计器,它本身由语音活动检测器 (VAD) 或类似算法驱动,如图 7 (a) 所示。
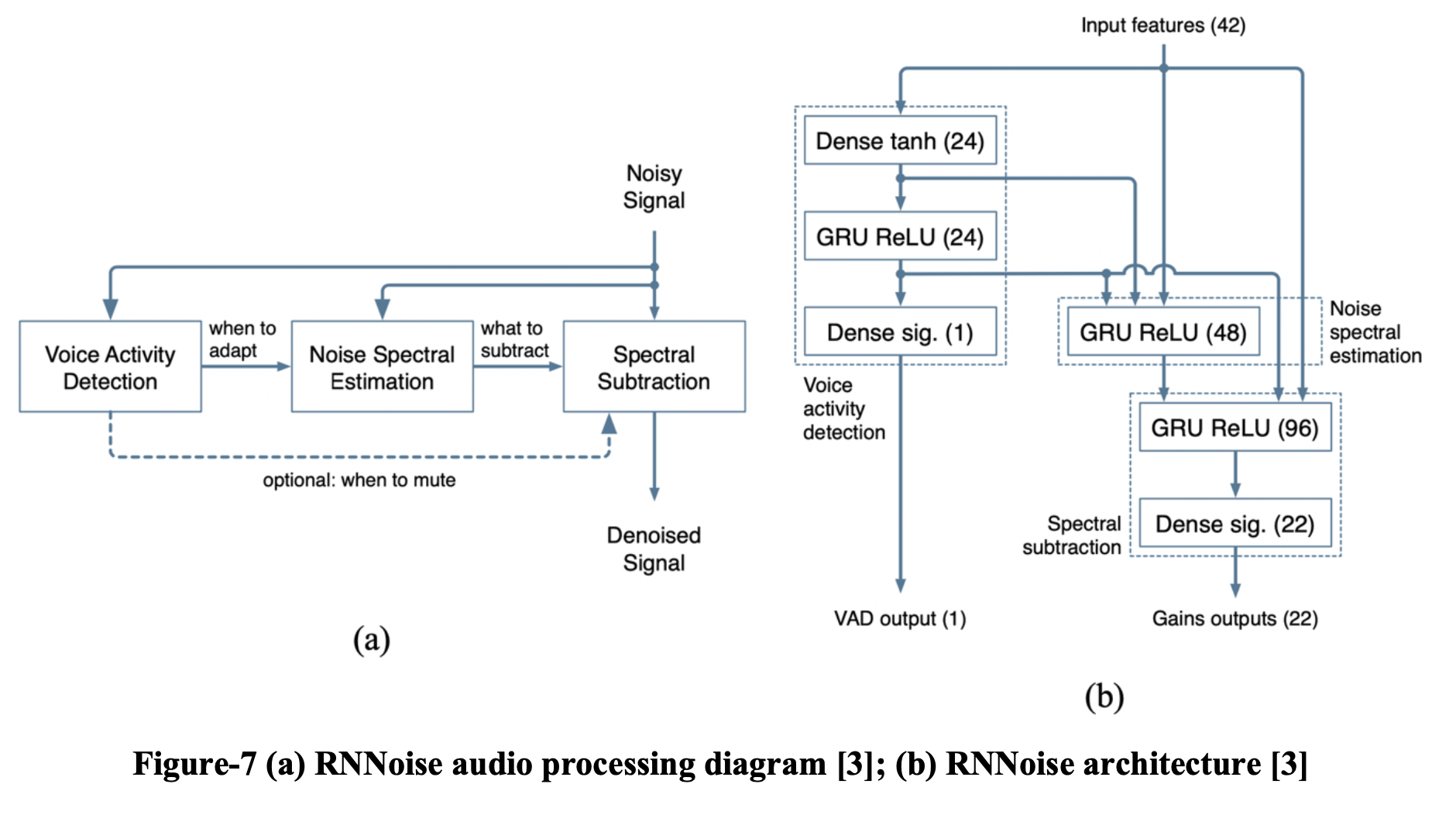
RNNoise 是 Jean-Marc [3] 提出的精简深度学习模型。 神经网络紧跟传统噪声抑制算法的结构,如图7(b)所示。 该设计基于以下假设:三个循环层各自负责图 7 (a) 中的一个基本组件。 它总共包括215个单元,4个隐藏层,最大层有96个单元。 值得注意的是,增加单元数量并没有显着提高噪声抑制的质量。 然而,损失函数和我们构建训练数据的方式对最终质量有很大影响(第 3.3 章)。我们实现的模型是基于 RNNoise 的,因为它是商业机密,我无法提供任何细节。
3.2 - 音频处理
RNNoise 将一帧嘈杂的音频作为输入并输出一帧降噪语音。 用 FFT 提取特征后,将输入馈送到 RNN 进行处理,然后在 IFFT 后生成输出。 尽管这个精简模型的参数只有 90k,但它在 PESQ 指标下取得了卓越的性能。
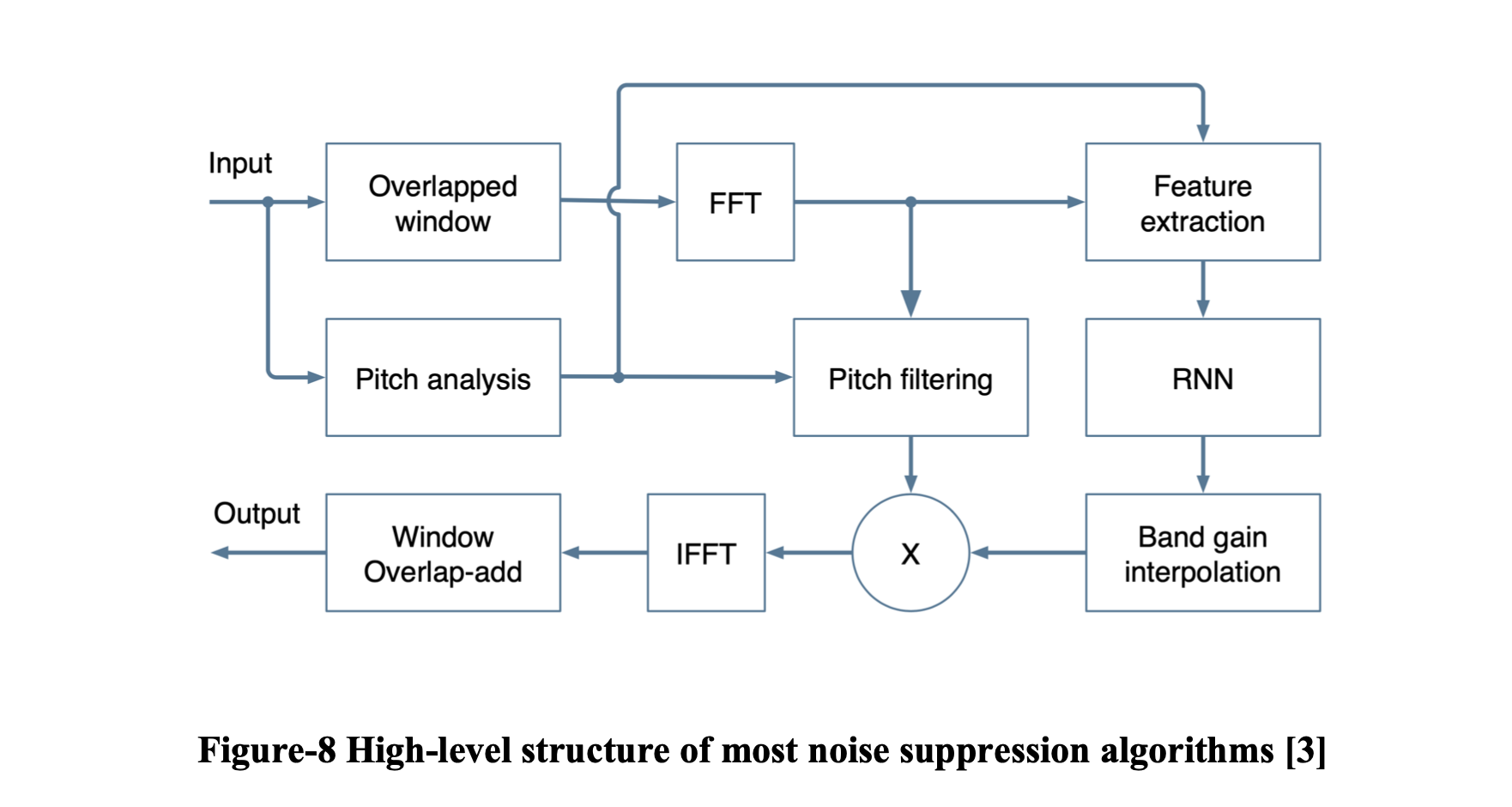
值得注意的是,有两个重叠的窗口应用于输入流。 在 FFT 之前应用,第一个窗口是为了避免频率泄漏。 第二个窗口添加在输出之前,具有音频平滑功能。 使用这些窗口,输出音频流畅且没有伪影。
3.3 - 训练
3.3.1 训练数据
我们的训练集是从 8 小时的干净语音和 4 小时的纯噪音中随机生成的。 clean speech 文件包括 125 个不同口音的男性和女性英语演讲者。 纯噪声文件由 15 类环境噪声组成,包括 babble 噪声、汽车噪声和街道噪声。 为避免过度拟合,训练集将在每个训练周期开始时重新采样。
3.3.2 优化流程
用于训练的损失函数决定了网络在无法准确确定正确增益时如何权衡过度衰减与衰减不足。 虽然在优化 [0, 1] 范围内的值时通常使用二元交叉熵函数,但这不会产生好的增益结果,因为它不符合它们的感知效果 [3]。 对于网络的 VAD 输出,我们使用标准的交叉熵损失函数。 使用 Keras 库 [13] 和 TensorFlow 后端 [14] 进行训练。
3.3.3 收敛
我们的模型一直在配备 1 个 Intel Core i9-9900K CPU 和 1 个 Nvidia RTX 2080 Ti GPU 的 Linux 服务器上进行训练。 对于每个 epoch,我们随机采样 50M 帧,其中每 1500 帧是连续的。 在 200 个 epoch 之后,模型在训练集和验证集上都收敛了。
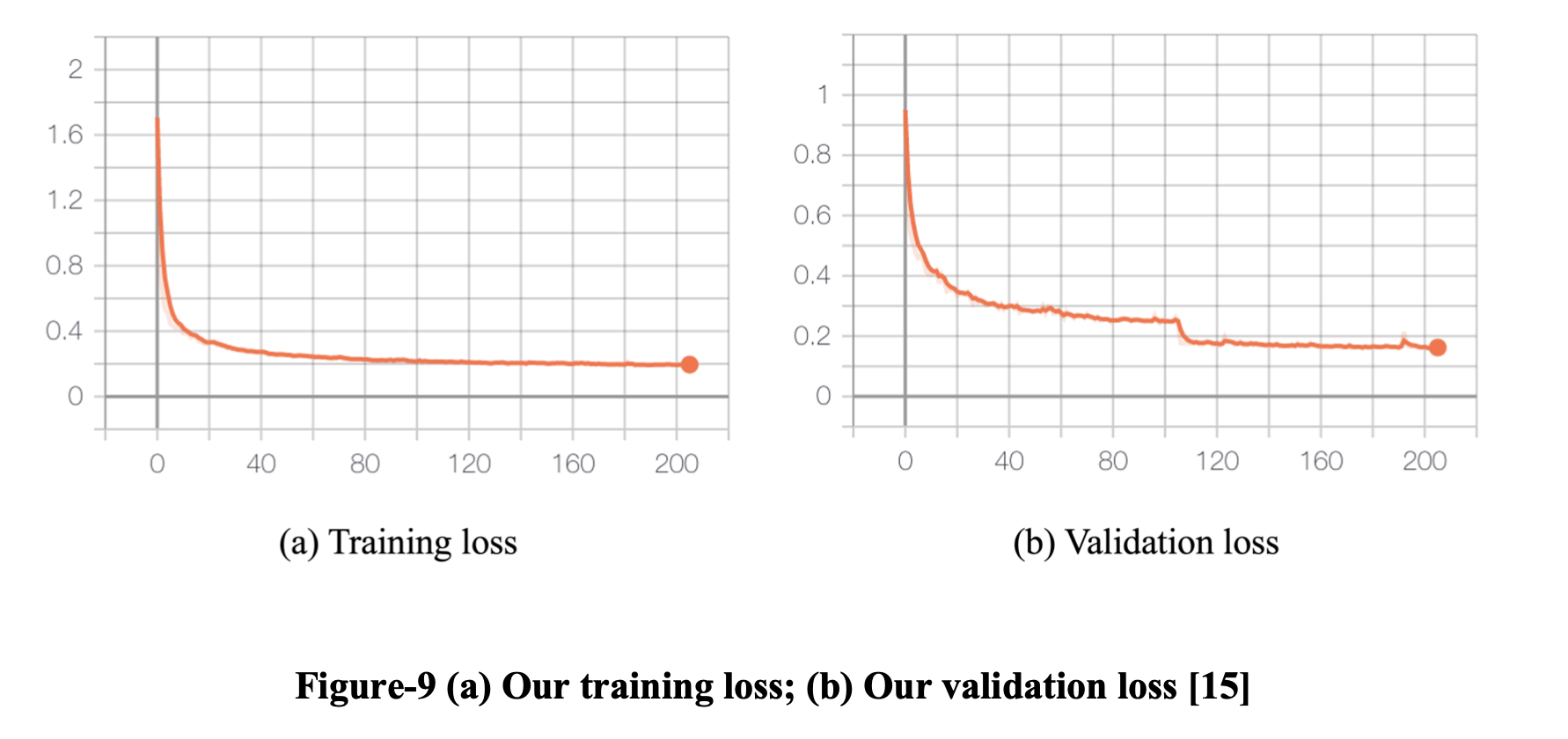
当前 20 个连续 epoch 的损失方差小于 2e-5 时,我们认为模型已经收敛。 我们的模型在 92 个 epoch 后收敛。
3.4 - 评估
3.4.1 数据准备
我们的评估集是从 1 小时的干净语音和特定类型的噪音中随机生成的。 干净的语音文件包括 38 位不同口音的男性和女性英语演讲者。 噪声是来自与训练集相同的噪声文件的特定环境噪声,包括喋喋不休的噪声、风噪声和街道噪声。 每个评估集由图 2 中 5 个不同 SNR 级别的噪声文件组成。 评估结果是每个 SNR 级别的 15 个噪声文件的平均性能。我们的评估使用 PESQ 作为指标并以 16k 采样率评估文件。
3.4.2 结果
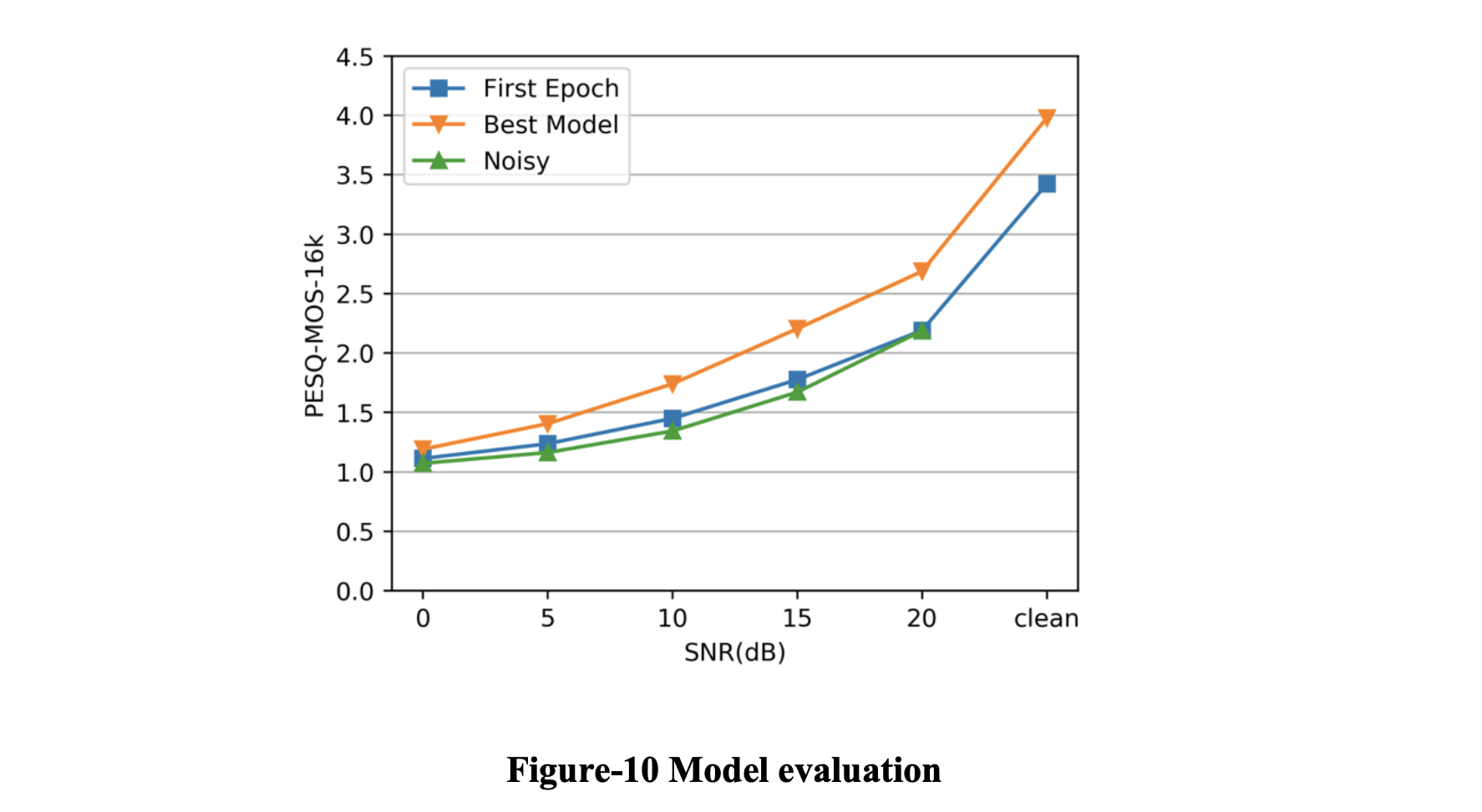
我们使用一种非常直观的方式来评估模型。 经过训练,模型的性能有了明显的提升。 即使在糟糕的情况下(SNR = 0),模型的降噪能力仍然得到了提升。
3.5 – 最佳帧长
3.5.1 帧长范围
傅立叶变换 (FT) 要求输入信号稳定。 但声音不稳定:嘴巴一动,信号的特性就发生了变化。 但是在比较短的时间内,嘴巴的运动速度并没有那么快,语音信号可以算是稳定的,满足了FT的要求。 帧长必须满足两个条件:
- 宏观上要足够短,才能保证帧内信号稳定。 如前所述,唇形的变化是信号不稳定的原因,因此在一帧期间唇形不能发生明显变化,即帧的长度应小于音素的长度。 在正常语速下,一个音素的持续时间约为50~200毫秒,因此帧长一般小于50毫秒。
- 在微观上,它必须足够长以包含足够的振动周期,因为频率需要重复足够多的次数才能被 FT 分析。 声音的基频对于男声大约是 100 赫兹,对于女声大约是 200 赫兹。 时间周期分别为10毫秒和5毫秒。 由于一帧包含多个周期,一般至少为20毫秒。
这样我们就知道帧长一般为20-50毫秒。 在 RNNoise 中,它对一个窗口应用 FFT,窗口的大小是帧长度的 2 倍,因此它的帧长度必须在 10-25 毫秒的范围内。由于 RNNoise 使用 50% 的重叠窗口,它的输入延迟就是它的帧长度。 在接下来的部分中,我将使用 16ms 模型来表示帧长为 16ms(FFT 的窗口长度为 32ms)的 RNNoise 模型,并使用 10ms 模型来表示帧长为 10ms(FFT 的窗口长度为 20ms)。
3.5.2 实验
在这个实验中,我们比较了 16ms 模型和 10ms 模型在 RNNoise 上的性能。 16ms 模型具有与 10ms 模型完全相同的超参数,除了帧长度。 在模型经过充分训练后,我们在相同的评估集上对它们进行评估。
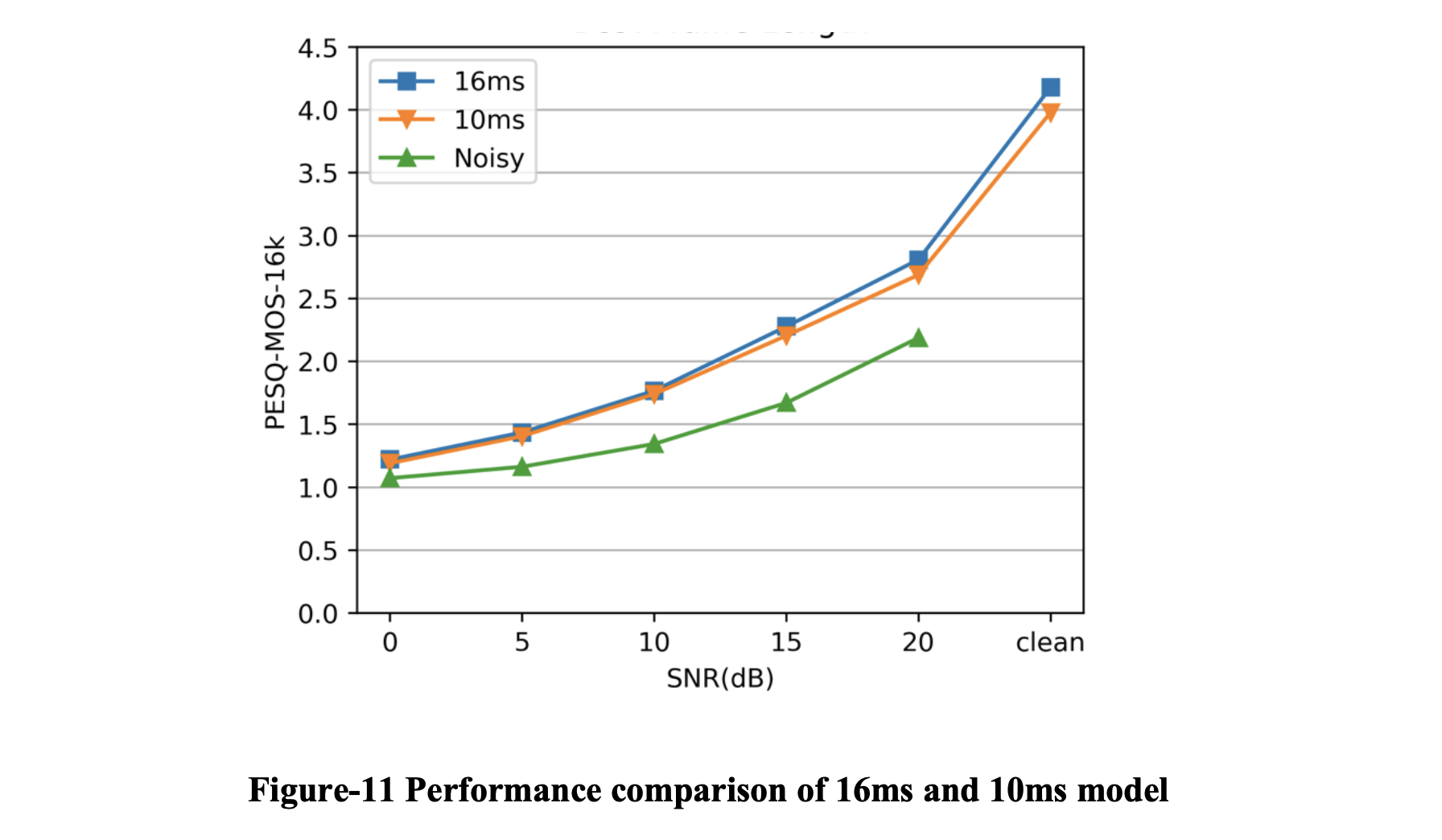
16ms 模型优于 10ms 模型,尤其是在高 SNR 情况下,因此最佳帧长度为 16ms。这个结果是合理的,也是意料之中的:在进行FFT时,帧长越大,FFT精度越高,也就是每一帧的波形被更多的谐波描述,所以会有更好的结果。
第 4 章 极低延迟算法
在本节中,我们提出了一种新算法作为显着减少基于 RNN 的深度学习模型延迟的解决方案。 对于任何具有 10 毫秒输入延迟的 RNN 模型,我们提出的算法可以有效地将输入延迟降低到小于 1 毫秒,而性能成本却很小。
4.1 - 算法
这部分是商业机密,我不能透露任何信息。
4.2 - 结果
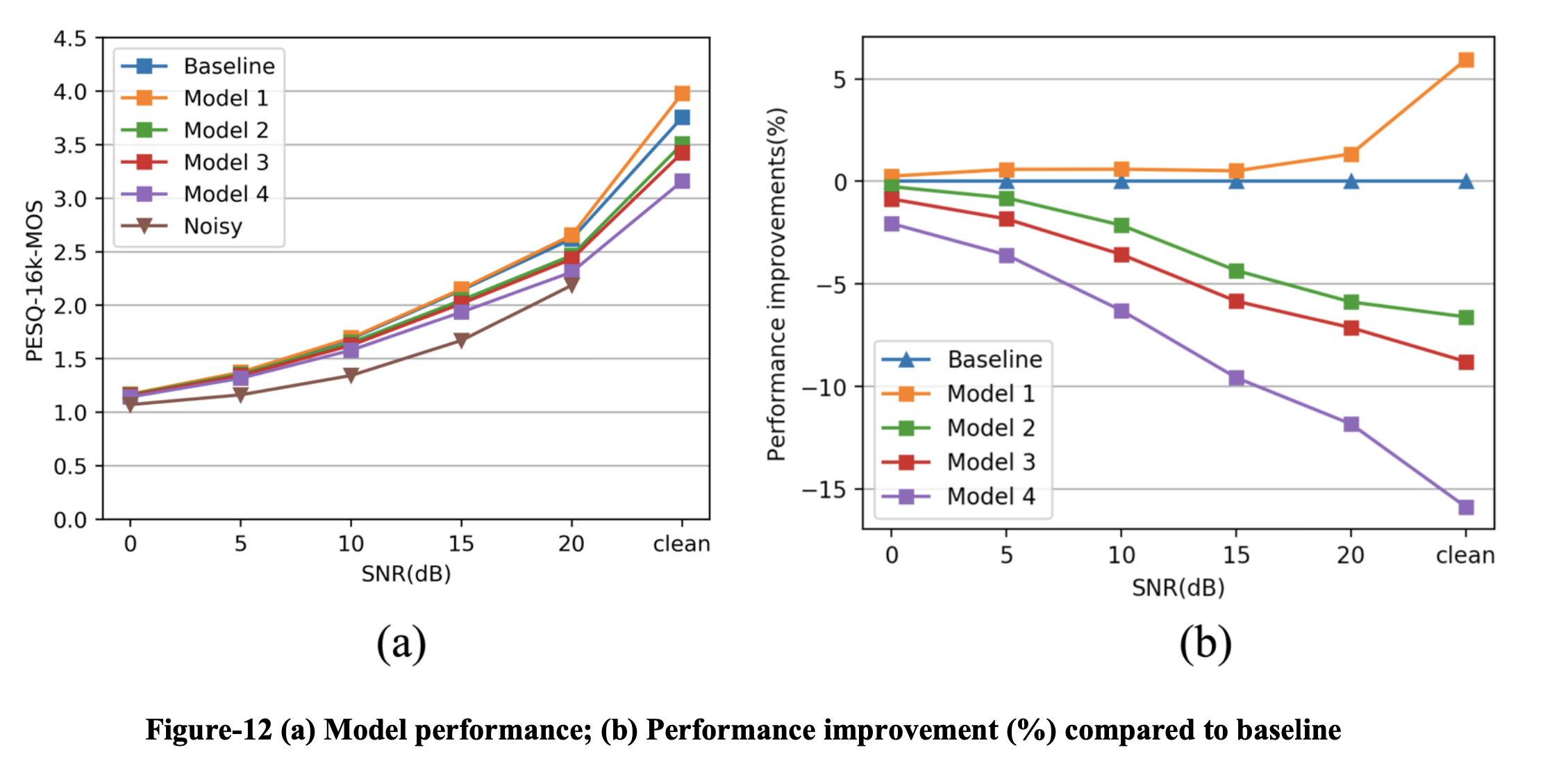
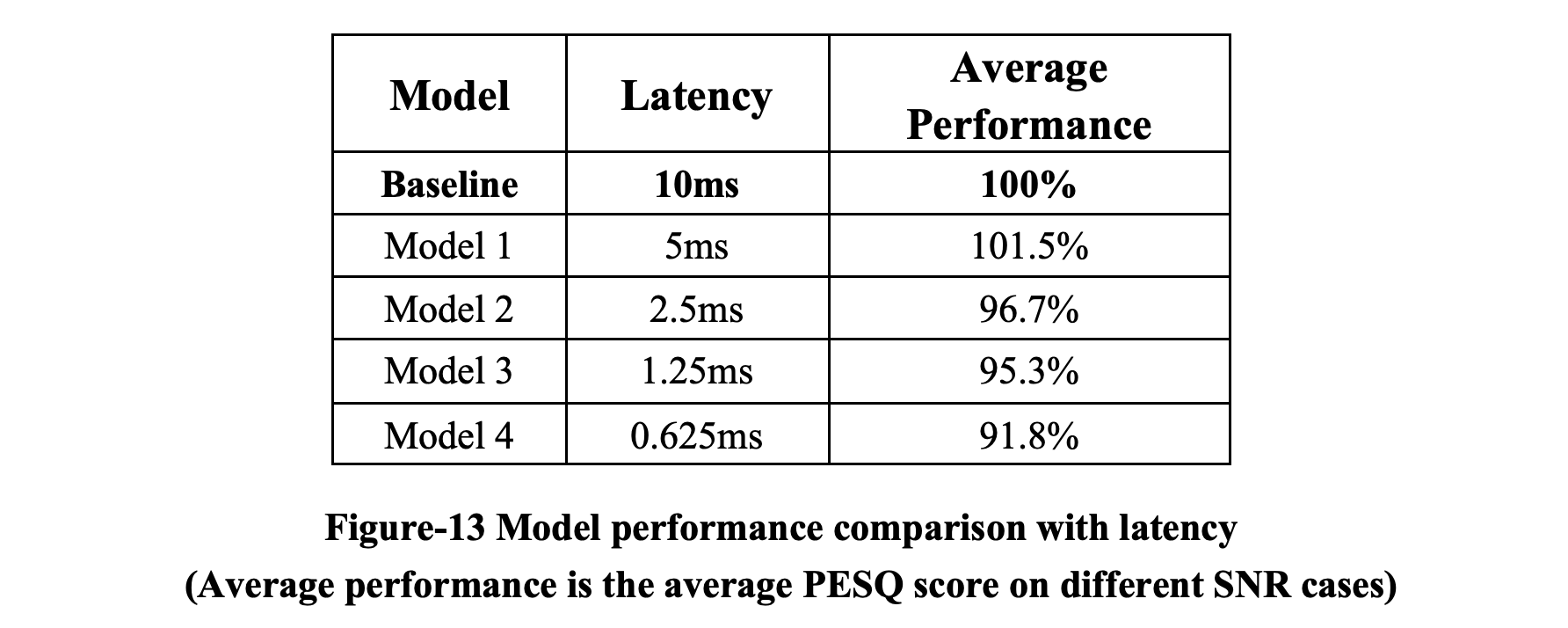
我们选择之前 10ms 良好训练的 RNNoise 模型作为基线。 我们使用我们提出的算法评估 4 个模型,并将它们与基线进行比较。 我们的算法可以以可接受的性能成本大大减少输入延迟。
第 5 章 总结与回顾
我和我的团队提出了一种通用算法,可以大大降低基于 RNN 的模型的输入延迟,并且已被证明是有效的。 希望该算法能够大大降低具有极低延迟要求的应用程序的门槛,例如基于 RNN 的深度学习模型的助听器。
今年夏天,我有幸遇到了 Evoco Labs。 在这个年轻而热情的团队里,我很容易与同事相处。 这里没有官僚作风,就像一群小伙伴一起追逐梦想。 我衷心希望他们的梦想早日实现。
衷心感谢我的企业导师路丛希,他给了我很大的启迪和启发。 他给我提供了各种自我驱动的任务,让我自己推动自己最感兴趣的任务。 感谢这次实习,让我得以一窥语音增强和工薪阶层的生活。 它在很多方面推动了我前进。
在代码方面,我开始思考如何写出高效的代码,我开始明白什么是好的代码风格,我开始尝试增强我的代码的通用性。
在项目层面,我开始明白如何提出一个有意义的项目,如何将长期计划落实为短期小目标,如何将目标细化为具体任务,如何与团队同步工作,最重要的是 ,如何封装和借鉴整个项目。
关于个人规划,我已经不那么拘泥于之前的规划了,开始迷茫了。 不要误会我的意思,这不是一件坏事。 以前对行业一窍不通,做的决定有些武断。 在产品团队工作了一段时间后,我逐渐理解了工业界和学术界截然不同的需求。 我坚信这次经历带来的迷茫是暂时的,它会让我更加清楚自己想要什么,引导我做出更加理性的决定。
这个夏天,我经历了很多。 第一次找工作,第一次租房,第一次签合同,第一次给自己推项目,第一次体验工薪阶层生活, 第一次领到工资,第一次过自己的生活……这些经历让我明白了我需要从大学学到什么,让我明白了企业对员工的期望,也启发了我思考在剩下的三个学年里我需要如何成长。
参考文献
[1] “Hearing Aids,” Orka, 2020. [Online]. Available: https://www.hiorka.com/. [Accessed: 28-Aug-2020].
[2] D. Wang and J. Chen, “Supervised Speech Separation Based on Deep Learning: An Overview,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 10, pp. 1702-1726, Oct. 2018, doi: 10.1109/TASLP.2018.2842159.
[3] J. Valin, “A Hybrid DSP/Deep Learning Approach to Real-Time Full-Band Speech Enhancement,” 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, 2018, pp. 1-5, doi: 10.1109/MMSP.2018.8547084.
[4] J. Valin and J. Skoglund, “LPCNET: Improving Neural Speech Synthesis through Linear Prediction,” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019, pp. 5891-5895, doi: 10.1109/ICASSP.2019.8682804.
[5] C. S. S. ([email protected]), “WAVE PCM soundfile format,” Microsoft WAVE soundfile format. [Online].
Available: http://soundfile.sapp.org/doc/WaveFormat/. [Accessed: 28-Aug-2020].
[6] Vorbis I specification. [Online].
Available: https://xiph.org/vorbis/doc/Vorbis_I_spec.html. [Accessed: 19-Aug-2020].
[7] A. W. Rix, J. G. Beerends, M. P. Hollier and A. P. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), Salt Lake City, UT, USA, 2001, pp. 749-752 vol.2, doi: 10.1109/ICASSP.2001.941023.
[8] C. H. Taal, R. C. Hendriks, R. Heusdens and J. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, 2010, pp. 4214-4217, doi: 10.1109/ICASSP.2010.5495701.
[9] Pennock, Scott. “Accuracy of the Perceptual Evaluation of Speech Quality (PESQ) algorithm.” [Online]
Available: http://wireless.feld.cvut.cz/mesaqin2002/full09.pdf [Accessed: 28-Aug-2020].
[10] O. Christopher, “Understanding LSTM Networks,” Understanding LSTM. Networks — Colah’s blog, 2015. [Online].
Available: http://colah.github.io/posts/2015-08-Understanding-LSTMs/. [Accessed: 28-Aug-2020].
[11] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[12] J. Chung, C. Gulcehre, K. H. Cho, and Y. Bengio, “Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling,” arXiv.org, 11-Dec-2014. [Online]. Available: https://arxiv.org/abs/1412.3555. [Accessed: 28-Aug-2020].
[13] Keras Team, “Keras documentation: Keras API reference,” Keras. [Online]. Available: https://keras.io/api/. [Accessed: 28-Aug-2020].
[14] Google, “API Documentation: TensorFlow Core v2.3.0,” TensorFlow. [Online]. Available: https://www.tensorflow.org/api_docs. [Accessed: 28-Aug-2020].
[15] Google, “Get started with TensorBoard: TensorFlow,” TensorFlow. [Online]. Available: https://www.tensorflow.org/tensorboard/get_started. [Accessed: 01-Sep-2020].